
타이타닉 데이터 셋을 이용한 결측치 확인, 지도학습
타이타닉 케글 경진대회 참여
데이터 받는 방법
메인 페이지의 ‘Data’ 탭을 누른 뒤, 아래로 스크롤 하면 우측 하단에 ‘Download All’을 누르면 데이터 압축 파일을 받을 수 있다.
⚠️ 교육/연습용으로 EDA를 하기 위한 데이터를 받을 때, 데이터 크기를 유의하자. 너무 큰 용량은 오히려 연습하기엔 어려울 수 있다.
타이타닉 데이터셋 호출
Train 데이터 셋과 Test 데이터 셋을 불러온다.
train = pd.read_csv("data/titanic/train.csv", index_col = "PassengerId")
test = pd.read_csv("data/titanic/test.csv", index_col = "PassengerId")
train과 test의 columns의 차이 확인
set(train.columns) - set(test.columns)
결과값 : {'Survived'}
test data에는 “Survived” columns가 없는 것을 확인 할 수 있음 ⇒ train 데이터를 학습하여 test에서 “survived”를 예측하는 것이 목표다.
# test와 train의 행의 개수 확인
train.shape[0]/test.shape[0]
# 결과값
2.1315789473684212
train의 데이터가 test보다 2배 이상 많은 것을 확인하였다.
Histogram을 통해서 데이터 분포도를 확인
train.hist(figsize = (12,6), bins = 50);
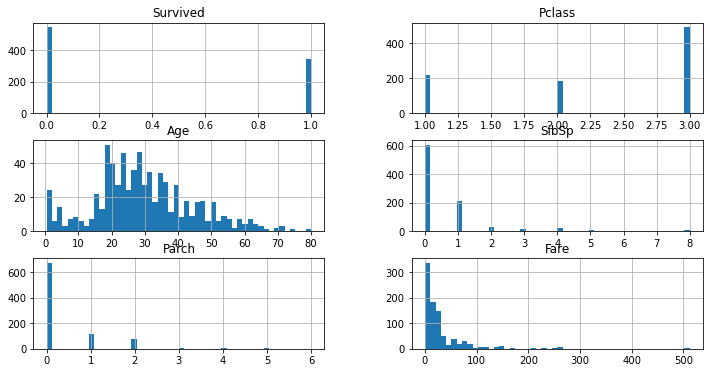
Survived에서 사망자가 생존자보다 높은 것을 확인 할 수 있으며, 나이는 20~30대에 분포가 많고, Pclass는 3이, 그리고 Parch, Fare와 SfbSp에 0이 높은 것을 확인할 수 있다.
test.hist(figsize = (12,6), bins = 50);
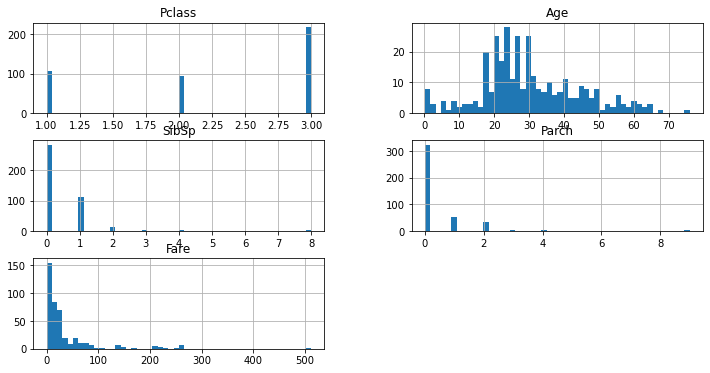
Test 데이터도 Train과 비슷한 분포도를 보이고 있다.
결측치 확인
isnull().sum()을 통해 데이터 셋의 결측치를 확인하고, 이를 시각화 하였다.
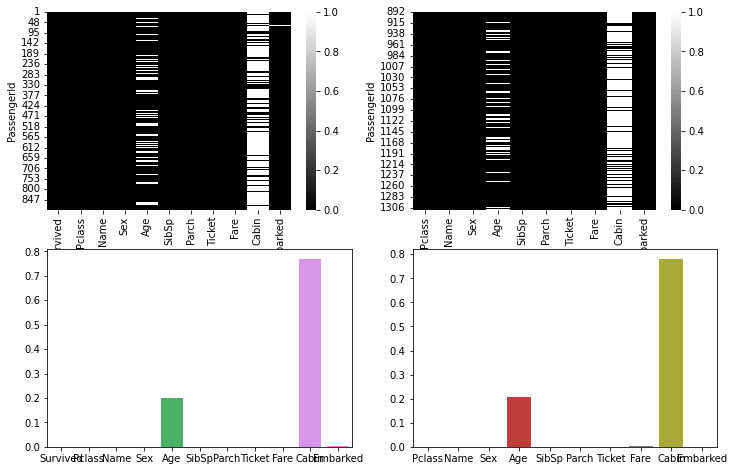
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(12, 8))
sns.heatmap(train.isnull(), cmap="gray", ax=axes[0, 0])
sns.heatmap(test.isnull(), cmap="gray", ax=axes[0, 1])
sns.barplot(data=train.isnull(), ax=axes[1, 0], ci=None)
sns.barplot(data=test.isnull(), ax=axes[1, 1], ci=None)
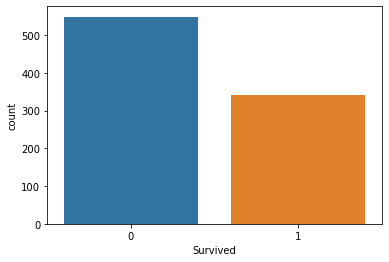
정답값 빈도수
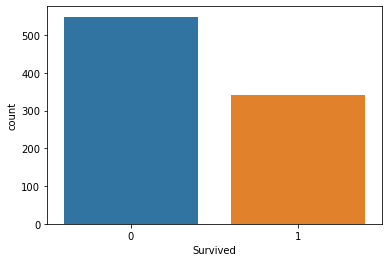
Value_counts()를 통해서 생존자의 값을 확인한다.
train["Survived"].value_counts()
결과값
0 549
1 342
Name: Survived, dtype: int64
countplot을 사용하여 시각화까지 진행하였다.
sns.countplot(data = train, x = "Survived")
제출하기
제출할 파일을 불러오고 submit이라는 변수에 담아둔다.
submit = pd.read_csv("data/titanic/gender_submission.csv")
print(submit.shape)
제출할 파일을 다음과 같이 수정한다.
# 인덱스 값이 같아야 값을 할당할 때 바로 적용이 되는데
# 값이 달라서 tolist()를 해주고 순서대로 값을 적어준다.
submit["Survived"] = (test["Sex"] == "female").astype(int).tolist()
submit.head()
수정된 submit을 csv로 만들어서 저장한다.
submit.to_csv("data/titanic/first_submission.csv", index = False)
파일을 해당 케글 경진대회 사이트에서 ‘Submit Predictions’를 누른 후 파일을 업로드하면 제출이 완료되고 점수를 확인 할 수 있다.
데이터 전처리 방법
- 정규화(Normalization) : 숫자 스케일의 차이가 클 때 값을 정규분포로 만들어 주거나 스케일 값을 변경해 주는 것
- 이상치(Outliers) : 이상치를 제거하거나 대체
- 대체(Imputation) : 결측치를 다른 값으로 대체
- 인코딩(Encoding) : 호칭, 탑승지의 위치, 문자 데이터를 수치화, 너무 범위가 큰 수치 데이터를 구간화 해서 인코딩 할 수도 있습니다.
Accuracy
- (실제값 == 예측값) => 평균(올바르게 예측한 샘플 개수 / 전체 샘플 개수)
- 올바르게 예측한 데이터 개수 / 전체 샘플 개수 = TP+TN / TP + TN + FP + FN
결측치 확인
Lable 값 빈도수 확인
sns.countplot(data = train, x = "Survived")
결측치 확인
isnull()로 bool type으로 변환한 뒤, 평균값(mean())을 계산하고 *100을 하여 퍼센티지를 확인한다.
train.isnull().mean()*100
결과값
Survived 0.000000
Pclass 0.000000
Name 0.000000
Sex 0.000000
Age 19.865320
SibSp 0.000000
Parch 0.000000
Ticket 0.000000
Fare 0.000000
Cabin 77.104377
Embarked 0.224467
dtype: float64
test.isnull().mean()*100
결과값
Pclass 0.000000
Name 0.000000
Sex 0.000000
Age 20.574163
SibSp 0.000000
Parch 0.000000
Ticket 0.000000
Fare 0.239234
Cabin 78.229665
Embarked 0.000000
dtype: float64
지도학습 과정을 적용하여 타이타닉 데이터 셋 진행
정답값을 지정
label_name 이라는 변수에 예측할 컬럼의 이름을 담는다.
label_name = "Survived"
label_name
학습, 예측에 사용할 컬럼을 지정
머신러닝 내부에서는 연산이 불가능 하기 때문에 수치 데이터를 가진 컬럼만 호출한다.
train.select_dtypes(include = "number").columns
결과값
Index(['Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare'], dtype='object')
Binary encoding : 성별은 중요한 역할을 하는데 문자로 되어있으면 머신러닝 내부에서 연산을 할 수 없기 때문에 수치 데이터로 변환하는 인코딩 작업을 수행하도록 한다.
train["Gender"] = train["Sex"] == 'female'
test["Gender"] = test["Sex"] == 'female'
feature_names라는 변수에 학습과 예측에 사용할 컬럼명을 가져온다.
feature_names = ['Pclass', 'Age', 'SibSp', 'Parch', 'Fare', 'Gender']
학습, 예측 데이터셋 만들기
X_train과 X_test: feature_names 에 해당되는 컬럼만 train에서 가져온다. 이 때, 결측치가 있기 때문에 채워줘야 하는데 의미 있는 값으로 채우는 것이 가장 좋지만, 현재 단계에선 파악이 불가하기에 우선 ‘0’으로 채운다.
# 학습(훈련)에 사용할 데이터셋 예) 시험의 기출문제
X_train = train[feature_names].fillna(0)
X_test : feature_names 에 해당되는 컬럼만 test에서 가져온다. 예측에 사용할 데이터셋 예) 실전 시험문제
test 에 있는 데이터의 행은 삭제를 하면 안된다. 삭제를 하면 예측해야 하는 문제인데 예측을 못 하기 때문에 경진대회 데이터이면 제출해야 하는 값이 부족하기 때문에 제출 했을 때 오류가 발생한다.
X_test = test[feature_names].fillna(0)
y_train : label_name 에 해당 되는 컬럼만 train에서 가져온다.
# 학습(훈련)에 사용할 정답 값 예) 기출문제의 정답
y_train = train[label_name]
머신러닝 알고리즘 가져오기
Decision Tree Classifier(결정 트리)를 이용하여 학습을 시킨다.
# max_depth == 1 트리의 깊이를 의미.
# max_features == 0.9 라면 전체 피처의 90% 만 사용.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state = 42)
fit을 시켜서 학습을 하고 예측을 시킨다.
# X_train과 y_train을 fit하는 과정
model.fit(X_train, y_train)
# fit한 모델을 토대로 X_test 데이터에 예측결과를 y_predict에 담는다.
y_predict = model.predict(X_test)
y_predict[:5] # 출력값이 많기 때문에 5개 값만 출력
결과값
array([0, 0, 1, 1, 0], dtype=int64)
log
2진 로그를 사용할 예정
np.log2(2)
결과값 = 1
np.log2(4)
결과값 = 2
np.log2(8)
결과값 = 3
2진 로그, 10진로그, e로그의 공통점
- x가 1 일 때 y는 0이다.
- x 는 0보다 큰 값을 갖는다.
- x가 1보다 작을 때 y값이 마이너스 무한대로 수렴한다.
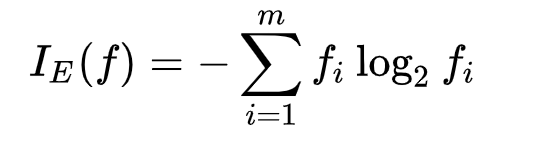
2 섀넌의 엔트로피 : 2 개의 공정한 동전을 던질 때 정보 엔트로피는 발생 가능한 모든 결과의 개수에 밑이 2 인 로그를 취한 것과 같다. 2 개의 동전을 던지면 4 가지 결과가 발생할 수 있고, 엔트로피는 2 비트가 된다. 일반적으로 정보 엔트로피는 모든 발생가능한 결과의 평균적인 정보가 된다.
엔트로피 계산법
# 앞에 (-)를 붙이는 이유는 log의 x값이 1 이하로 내려가면 음수로 나오기 때문에 (-)를 붙혀 양수로 전환한다.
-((구하고자 하는 확률)*np.log2(구하고자 하는 확률) + (1-구하고자 하는 확률)*np.log2(1-구하고자 하는 확률))
위에서 학습 시킨 모델을 plot_tree를 통해서 시각화를 한다.
from sklearn.tree import plot_tree
plt.figure(figsize = (12,6))
plot_tree(model, max_depth = 4, fontsize = 14, filled = True, feature_names = feature_names)
plt.show()
그리고 루드노드의 엔트로피를 구한다.
# 엔트로피가 0은 다른 값이 섞여있지 않음을 의미한다.
-((549/891)*np.log2(549/891) + (1-549/891)*np.log2(1-549/891))
결과값 : 0.9607079018756469
지니 불순도의 값도 구해본다.
1-(549/891)**2 - (341/891) ** 2
결과값 : 0.4738732883139918
트리 아래로 내려 갈 수록 지니불순도와 엔트로피의 값이 작아진다.
💡 지니불순도와 엔트로피를 사용하는 목적
분류를 했을 때 True, False 로 완전히 나뉘지 않는데 이 때 값이 얼마나 섞여있는지 수치로 확인하기 위해서이고, 0에 가까울 수록 다른 값이 섞여있지 않은 상태입니다. 분류의 분할에 대한 품질을 평가하고 싶을 때 사용한다.
0에 가까운지를 본다. 지니 불순도는 0.5일 때 가장 값이 많이 섞여있는 상태이며, 엔트로피는 np.log2(클래스 갯수) 값과 같을 때가 가장 많이 섞여있는 상태로 보면 된다. 0에 가까운지를 보면 되고, 트리를 보게 되면 트리 아래로 갈 수록 0에 가까워진다. 지니 불순도나 엔트로피가 0이 되면 트리 분할을 멈춘다. 다만, 지정한 max_depth 값이 되면 분할을 멈춥니다.
엔트로피는 지니계수보다 더 엄격하게 검사하기 위해서 사용.
🤔 프로젝트 등을 할 때 지니불순도 등을 참고하게 되나? 캐글이나 데이콘 등에 제출하기 전에 시각화를 해보고 그 모델이 얼마나 잘 나뉘었는지 여러가지로 평가해 볼 수 있는데 이 때 함께 참고해 볼 수 있다. 이 때 함께 참고해 볼 수 있는 것은 피처 중요도, 교차검증(cross validation) 값 등을 참고할 수 있겠다.
파생변수 만들기
가족의 수를 “FamilySize”, 성별을 “Gender” 라는 column안에 담아두었다.
# Parch : 부모와 자식수
# SibSp : 형제자매 수
train["FamilySize"] = train["Parch"] + train["SibSp"] + 1
test["FamilySize"] = test["Parch"] + test["SibSp"] + 1
train["Gender"] = train["Sex"] == "female"
test["Gender"] = test["Sex"] == "female"
이름 앞에 오는 호칭에 대한 파생변수를 “Title”이라는 Column안에 담아두었다.
train["Title"] = train["Name"].map(lambda x : x.split(".")[0].split(",")[1].strip())
test["Title"] = test["Name"].map(lambda x : x.split(".")[0].split(",")[1].strip())
