
타이타닉 데이터 셋의 파생변수 만들기, One-Hot-Encoding, 결측치 대체, 머신러닝 알고리즘 적용
지난 포스팅에서 이어짐(수정예정)
생성한 파생변수가 Train과 Test에 동일하게 있는지를 확인하기 위해 set 기능을 사용하였다.
# train에만 있는 호칭을 확인하기 위한 코드
set(train["Title"].unique()) - set(test["Title"].unique())
결과값 :
{'Capt',
'Don',
'Jonkheer',
'Lady',
'Major',
'Mlle',
'Mme',
'Sir',
'the Countess'}
# test에만 있는 호을 확인하기 위한 코드
set(test["Title"].unique()) - set(train["Title"].unique())
결과값 : {'Dona'}
확인한 결과 꽤 많은 차이가 생기는 것을 확인하였다. 그러면, 차이의 숫자가 얼마나 있는지 확인하기 위해 각각 value_counts()를 통해서 확인해보자.
train["Title"].value_counts()
결과값 :
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Mlle 2
Major 2
Col 2
the Countess 1
Capt 1
Ms 1
Sir 1
Lady 1
Mme 1
Don 1
Jonkheer 1
Name: Title, dtype: int64
test["Title"].value_counts()
결과값 :
Mr 240
Miss 78
Mrs 72
Master 21
Col 2
Rev 2
Ms 1
Dr 1
Dona 1
Name: Title, dtype: int64
train set을 보면 2개 이하인 변수명이 여러 존재하는 것을 확인할 수 있다. 전처리를 위해 2개 이하(2개나 1개만 있는 호칭)는 Etc로 묶어주도록 한다. 데이터 전처리를 할 때는 train을 기준으로 한다. (현실 세계에서 test 는 아직 모르는 데이터이기 때문에)
title_count = train["Title"].value_counts()
not_etc = title_count[title_count > 2].index
# ~ : '해당 내용을 제외한' 이라는 의미를 가지고 있다. 즉, trian.loc안에 담겨진 행은 not_etc에
# 포함되지 않은 행을 Etc로 바꿔달라는 코드이다.
train["TitleEtc"] = train["Title"]
train.loc[~train["Title"].isin(not_etc), "TitleEtc"] = "Etc"
# 주피터 노트북에선 ESC + F를 누르면 Find and Replace기능을 사용할 수 있다.
test["TitleEtc"] = test["Title"]
test.loc[~train["Title"].isin(not_etc), "TitleEtc"] = "Etc"
Cabin도 앞글자만 따와서 Cabin_initial이라는 컬럼에 담아두도록 한다.
train["Cabin_Initial"] = train["Cabin"].astype(str).map(lambda x : x[:1].upper().strip())
test["Cabin_Initial"] = test["Cabin"].astype(str).map(lambda x : x[:1].upper().strip())
# 강사님 해설
train["Cabin_Initial"] = train["Cabin"]
train["Cabin_Initial"] = train["Cabin_initial"].fillna("N").str[0]
test["Cabin_Initial"] = test["Cabin"]
test["Cabin_Initial"] = test["Cabin_initial"].fillna("N").str[0]
train 테이블과 test 테이블이 같은 값을 가졌는지를 확인해보자.
train["Cabin_Initial"].value_counts()
결과값 :
N 687
C 59
B 47
D 33
E 32
A 15
F 13
G 4
T 1
Name: Cabin_Initial, dtype: int64
test["Cabin_Initial"].value_counts()
결과값 :
N 327
C 35
B 18
D 13
E 9
F 8
A 7
G 1
Name: Cabin_Initial, dtype: int64
확인 결과, test 테이블에는 train의 “T”가 존재하지 않는다. 하지만, T값이 하나만 있기 때문에 fare의 평균값을 구한 뒤, 가장 근접한 Cabin_Initial로 대체하도록 하자.
# Cabin_Initial Columns의 평균 Fare값을 구하기 위한 코드. Groupby를 사용하도록 하자.
train.groupby(["Cabin_Initial"])["Fare"].mean()
결과값 :
Cabin_Initial
A 39.623887
B 113.505764
C 100.151341
D 57.244576
E 46.026694
F 18.696792
G 13.581250
N 19.157325
T 35.500000
Name: Fare, dtype: float64
확인한 결과, A와 가장 근접하기 때문에 T를 A로 대체해주고 값이 일치하는지 확인한다.
# replace 기능을 이용하여 T를 A로 대체한다.
train["Cabin_Initial"] = train["Cabin_Initial"].replace("T", "A")
# 정상적으로 값이 잘 입력되었는지 확인하자. 정상적으로 입력이 되었다면, 각 테이블의 nunique
# 값이 동일하게 출력될 것이고, set을 이용하여 차이를 구하면 남는 unique가 없을 것이다.
print(train["Cabin_Initial"].nunique(), test["Cabin_Initial"].nunique())
set(train["Cabin_Initial"].unique()) - set(test["Cabin_Initial"].unique())
결과값 :
8 8
set()
One-Hot-Encoding
한 개의 columns 안에 들어있는 변수가 분류형이면 모델이 학습할 때 문자는 인식을 하지 못해서 학습할 때 에러가 발생한다. 그렇기 때문에 그러한 분류형 변수들을 수치형 변수로 만들어주는 과정 중 하나가 One-Hot-Encoding이다. One-Hot-Encoding의 작동 원리는 다음과 같다고 볼 수 있다.
# One-Hop-Encoding이 동작하는 방식입니다.
train["Embarked_S"] =train["Embarked"] == "S"
train["Embarked_C"] =train["Embarked"] == "C"
train["Embarked_Q"] =train["Embarked"] == "Q"
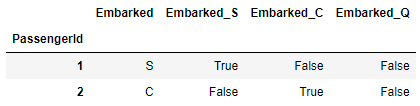
train[["Embarked", "Embarked_S", "Embarked_C", "Embarked_Q"]].head(2)

Embarked 컬럼 안의 변수 (S, C, Q)를 각각 새로운 컬럼(Embarked_S, Embarked_C, Embarked_Q)으로 만들어 해당 컬럼이 해당 변수(Embarked_S = S)가 있으면 True, 없으면 False로 표기하는 방식으로 나타낸다.
test["Embarked_S"] =test["Embarked"] == "S"
test["Embarked_C"] =test["Embarked"] == "C"
test["Embarked_Q"] =test["Embarked"] == "Q"
train[["Embarked", "Embarked_S", "Embarked_C", "Embarked_Q"]].head(2)
pd.get_dummies
One-Hot-Encoding을 판다스에서 지원하는 코드이다. 또한, 인코딩된 데이터의 타입은 object이다.
s = pd.Series(list('abca'))
pd.get_dummies(s)
결과값 :
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
⚠️ train에만 등장하는 호칭은 학습을 해도 test에 없기 때문에 예측에 큰 도움이 되지 않습니다. train 에만 등장하는 호칭을 피처로 만들어 주게 되면 피처의 개수가 늘어나는데 불필요한 피처가 생기기도 하고 데이터의 크기도 커지기 때문에 학습에도 시간이 더 걸립니다. 너무 적게 등장하는 값을 피처로 만들었을 때 해당 값에 대한 오버피팅 문제도 있을 수 있습니다. train과 test의 피처 개수가 다르면 오류가 발생합니다
원핫인코딩을 할 때 train, test피처의 개수와 종류가 같은지 확인이 필요합니다. 예를 들어 train피처는 수학인데, test피처는 국어라고 하면 피처의 개수가 같더라도 다른 종류 값이기 떄문에 제대로 학습할 수 없습니다. 피처를 컬럼명으로 만들 떼도 제대로 만들어지지 않습니다.
결측치 대체
train table에 “Age”와 test table의 “Age”,”Fare”에 결측치가 존재하기 때문에 결측치를 채우도록 한다. 결측치를 채우는 이유는 결측치가 존재하면 머신러닝을 진행할 수 없기 때문이다. 채워지는 결측치 값은 상황에 따라 다르지만, 여기서는 간단하게 중앙값(median())을 사용하도록 하겠다.
⚠️ 현실세계에서 분석하는 데이터는 함부로 결측치를 채우는 것에 주의를 해야한다. 머신러닝 알고리즘에서 오류가 발생하지 않게 하기 위해 결측치를 채운 것이라 분석할 때도 채운다고 오해하면 안된다.
# train column에 결측치가 채워질 Age_fill 컬럼을 Age 컬럼 기준으로 해서 추가 생성.
train["Age_fill"] = train["Age"]
# 중앙값 사용
train["Age_fill"] = train["Age_fill"].fillna(train["Age"].median())
# train과 마찬가지로 test에서도 동일하게 진행한다.
# test에서는 Fare에서도 결측값이 있기 때문에 같이 진행한다.
test["Age_fill"] = test["Age"]
test["Fare_fill"] = test["Fare"]
#중앙값 사용
test["Age_fill"] = test["Age_fill"].fillna(test["Age"].median())
test["Fare_fill"] = test["Fare_fill"].fillna(test["Fare"].median())
# train과 test의 columns가 일치해야 머신러닝이 가능하기 때문에
# train의 fare에 결측치가 없더라도 동일한 column을 생성해주자.
train["Fare_fill"] = train["Fare"]
학습에 사용될 값 지정
label_name과 feature_names에 예측할 컬럼과 사용할 컬럼을 지정한다.
# label_name 이라는 변수에 예측할 컬럼의 이름을 담아주자.
label_name = "Survived"
# feature_names에는 전처리한 columns를 담아주자.
feature_names = ['Pclass','Embarked',
'FamilySize', 'Gender','TitleEtc', 'Cabin_Initial',
'Age_fill', 'Fare_fill']
모델에 사용될 X table은 get_dummies를 이용해서 만들어준다.
X_train = pd.get_dummies(train[feature_names])
X_test = pd.get_dummies(test[feature_names])
# 컬럼들이 일치하는지 확인해주자.
set(X_train.columns) - set(X_test.columns)
결과값 : 0
머신러닝 알고리즘 가져오기
간단하게 확인하기 위해 결정 트리를 사용해보기로 하였다.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=42)
from sklearn.model_selection import cross_val_score, cross_val_predict
y_valid_predict = cross_val_predict(model, X_train, y_train, cv=5, n_jobs=-1, verbose=1)
y_valid_predict[:5]
정확도 예측하기
(y_valid_predict == y_train).mean()
결과값 : 0.7665544332210998
학습 (훈련)
model.fit(X_train, y_train)
y_predict = model.predict(X_test)
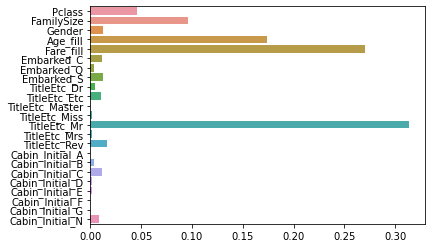
피저의 중요도도 시각화 해보자
sns.barplot(x = model.feature_importances_, y = model.feature_names_in_)
예측
# valid_accuracy : 여러번 모델을 수정하고 제출하다보면 valid 점수와 실제 캐글에 제출한 점수를
# 비교하기 쉽게 하기 위해 제출 파일이름에 valid score를 적어주면
# 캐글 점수와 비교하기 쉽습니다.
valid_accuracy = (y_train == y_valid_predict).mean()
valid_accuracy
결과값 : 0.7665544332210998
예측한 값을 케글에 제출
제출에 사용할 data set을 불러온다
submit = pd.read_csv("data/titanic/gender_submission.csv", index_col = "PassengerId")
제출할 submit의 “Survived” 컬럼에 예측한 값을 집어넣는다.
submit['Survived'] = y_predict
반복적인 파일저장과 잦은 파라미터 변경으로 바뀐 점수를 일괄적으로 저장해주는 명령어를 넣어주고 파일을 생성한다.
file_name = f"data/titanic/submit_{vaild_accuracy:.5f}.csv"
submit.to_csv(file_name)
생성된 파일을 캐글에 제출한다(11/01 글에 정리되어있음)
⚠️ 타이타닉 경진대회 관련 내용
타이타닉 대회는 워낙 유명한 대회라서 치팅도 많습니다. 그래서 1점에 가까운 점수는 거의 치팅으로 볼 수 있습니다. 200위 근처의 점수를 보면 0.82~0.81 정도가 있는데 이정도가 머신러닝의 다양한 기법을 사용해서 풀어볼 수 있는 현실적인 스코어 구간이라고 볼 수 있습니다.
💡 캐글에서 좋은 솔루션 찾는 법
1) Top 키워드로 검색 2) 솔루션에 대한 투표수가 많은 것 3) 프로필 메달의 색상
0504
결측치 대체
[interpolate](https://pandas.pydata.org/docs/reference/api/pandas.Series.interpolate.html?highlight=interpolate) : 보간법 중 하나. 특정 조건에 따라서 결측치를 채우는 명령어. fillna() 와 비슷한 역할을 하나 결측치를 어떻게 채울 것인지를 따로 설정을 해줄 수 있다.
💡 이전 값이나 다음 값으로 채울 수 있는데 이런 방법은 대부분 시계열데이터에서 데이터가 순서대로 있을 때 사용합니다. 예를 들어 일자별 주가 데이터가 있다고 가정할 때 중간에 빠진 날짜에 대한 데이터를 채울 때 사용하거나 예를 들어 순서가 있는 센서 데이터에서 수집이 누락되었거나 할 때 앞,뒤 값에 영향을 받는 데이터를 채울 때 사용합니다.
그런데 여기에서는 데이터가 순서대로 있다는 보장은 없지만 이렇게 채울수도 있다는 방법을 알아보겠습니다.
# fillna
# method : {'backfill', 'bfill', 'pad', 'ffill', None},
# Method to use for filling holes in reindexed Series
# pad / ffill: propagate last valid observation forward to next valid
# backfill / bfill: use next valid observation to fill gap.
# interpolate
# limit_direction : forward
# both 로 지정하면 위 아래 결측치를 모두 채워주고 나머지는 채울 방향을 설정합니다.
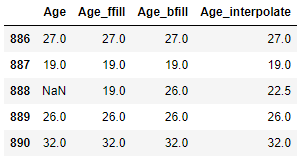
train["Age_ffill"] = train["Age"].fillna(method="ffill")
train["Age_bfill"] = train["Age"].fillna(method="bfill")
train["Age_interpolate"] = train["Age"].interpolate(method='linear', limit_direction='both')
train[["Age", "Age_ffill", "Age_bfill", "Age_interpolate"]].tail()
마찬가지로 test 테이블도 채우도록 한다.
test["Age_ffill"] = test["Age"].fillna(method="ffill")
test["Age_bfill"] = test["Age"].fillna(method="bfill")
test["Age_interpolate"] = test["Age"].interpolate(method='linear', limit_direction='both')
정답값, 예측값, 설정 및 학습/예측 데이터 셋 만들기
# 예측할 값인 Survived를 label_name에 담아둔다.
label_name = "Survived"
# 전처리한 columns를 feature_names에 담아둔다.
feature_names = ["Pclass", "Sex", "Age_interpolate", "Fare_fill", "Embarked"]
# X, y 데이터 셋을 만든다.
X_train = pd.get_dummies(train[feature_names])
X_test = pd.get_dummies(test[feature_names])
y_train = train[label_name]
머신러닝 알고리즘 가져오기
랜덤 포레스트를 이용하여 알고리즘을 호출한다.
from sklearn.ensemble import RandomForestClassifier
RandomForestClassifier(n_estimators=100, random_state=42, n_jobs = -1)
💡 랜덤 포레스트에 주로 사용되는 파라미터
n_estimators : 트리의 수 criterion: 가지의 분할의 품질을 측정하는 기능입니다. max_depth: 트리의 최대 깊이입니다. min_samples_split:내부 노드를 분할하는 데 필요한 최소 샘플 수입니다. min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수입니다. max_leaf_nodes: 리프 노드 숫자의 제한치입니다. random_state: 추정기의 무작위성을 제어합니다. 실행했을 때 같은 결과가 나오도록 합니다.
