
회귀 측정 공식, 하이퍼 파라미터 튜닝
회귀 측정 공식(회귀의 평가 방법)
MAE(Mean Absolute Error)
예측값과 실제값의 차이에 대한 절대값의 평균
오차에 절대값을 적용하는 이유 : (-)값이 있으면 제대로 된 평균값을 계산할 수 없음.
# y_train == 정답값, y_predict == 예측값
mae = abs(y_train - y_predict).mean()
MAPE(Mean Absolute Percentage Error)
(실제값 - 예측값 / 실제값)의 절대값에 대한 평균
mape = abs(y_train - y_predict) / y_train.mean()
MAPE값이 작을 수록 예측을 잘한 것으로 볼 수 있다.
MAPE를 사용하는 경우
- MSE(아래)가 절댓값에 비해 오차가 큰 값에 대해 패널티를 더 많이 줄 수는 있지만 예측비율 (부동산 가격 예시처럼 2배의 오차인지 10%의 오차인지)에 대해서 파악할 때
**MSE(Mean Squared Error)**
실제값 - 예측값의 차이의 제곱의 평균. MAE와 비슷해 보이나 제곱을 통해 음수를 양수로 변환함. 분산과 비슷한 양상을 보임. 오차의 값이 클 수록 패널티를 더 부여하는 방식.
# np.square : numpy의 함수 중 하나인 제곱.
# (y_train - y_predict) ** 2.mean(), pow(y_train - y_predict).mean()와 동일하다.
mse = np.square(y_train - y_predict).mean()
분산 : 확률변수가 기댓값으로부터 얼마나 떨어진 곳에 분포하는지를 가늠하는 숫자. 차이값의 제곱의 평균.
표준편차 : 분산을 제곱근한 것으로 정의한다.
분산과 MES의 차이 : 분산은 관측값에서 평균을 뺀 값을 제곱. 반면, MSE는 실제값에서 예측값을 뺀 값을 제곱.
**RMSE(Root Mean Squared Error)**
MSE 오차가 커질수록 값이 너무 커지는 것을 방지하기 위해 루트를 적용. MAE와 비슷한 수치의 스케일로 적용할 수 있음. 가장 많이 사용하는 방식
# mse ** 0.5 와 동일하다.
RMSE = np.sqrt(mse)
MAE와 MSE의 차이
1) 1억을 2억으로 예측 2) 100억을 110억으로 예측. 어느 것이 더 좋은 모델인가?
- MAE 1억을 2억으로 예측 → 1억차이, 100억을 110억으로 예측 → 10억차이
- MSE ⇒ 오차 1억의 제곱, 오차 10억의 제곱
1번은 2배 잘못 예측, 2번은 10% 잘못 예측.
회귀에서 Accuracy(정확도)를 사용하지 않는 이유 : 소수점 끝자리까지 정확하게 예측하기 어려워서.
❓ 멘토님의 회귀분석 관련 공식에 대한 답변
지금 배우는 MSE와 MAE 같은 지표는 “내가 만든 모델이 잘 예측했나?”라는 질문에서 시작합니다. 그럼 잘 예측했다라고 표현하고 싶은데 어떻게 표현할 수 있을까요?!
- 분류 분류의 경우에는 잘 정답값과 비교해서 많이 맞으면 잘 예측했다라고 말할 수 있겠죠. 이게 accuracy입니다.
- 회귀 회귀는 잘 예측했다! 라고 말하기에는 정답값에 딱 맞출 수가 없습니다. 그래서 오차가 적을수록 모델이 잘 예측했다! 라는 가정을 하고 그 오차를 MAE, MSE, RMSE와 같은 지표들이 나온겁니다. 이 맥락을 이해하시고 MAE, MSE, RMSE 등등 지표의 차이를 이해하시는 것이 좋을 것 같습니다. MSE와 MAE는 회귀모델이 잘 예측했는지 파악하기 위한 측정 지표입니다. 분산은 주어진 데이터의 분포를 확인하기 위한 수치이고, MSE나 MAE는 내가 예측한 지표와 정답값의 오차를 파악하기 위한 지표입니다
Pima Parameter Tunning
train_test_split
예제
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# train_test_split 의 옵션들
stratify(층화표지/층화추출) : train set과 test set를 분리할 때,
class 비율을 비슷 동일하게 나누는 기능
Subplots
# 칸이 2개인 도화지를 그림
# plt.subplots 결과가 튜플로 나오기 떄문에 앞의 것은 Fiogure, 다음 내용은 AxesSubplot을 의미합니다.
# nrows = 행으로 몇개를 그릴지를 정함
# ncols = 열으로 몇개를 그릴지를 정함
fig, axes = plt.subplots(nrows = 1, ncols = 2, figsize=(12,2))
sns.countplot(x = y_train, ax = axes[0]).set_title("train")
sns.countplot(x = y_test, ax = axes[1]).set_title("test");
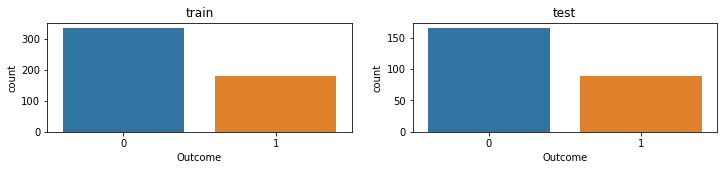
하이퍼 파라미터 튜닝
- 하이퍼 파라미터 최적화 : 알고리즘의 하이퍼 파라메터 값을 지정하고 지정된 값 중 좋은 성능을 내는 파라미터를 찾는 과정
- Grid Search : 지정된 구간에 대한 값에 대해서 탐색. 구간 외의 값을 놓칠 수 있음.
- Random Serach : 지정된 구간 외에 최적 값이 있을 때 그리드 서치로 찾지 못하는 단점을 보완하여 랜덤한 값들을 지정하고 성능 평가하여 최적의 파라미터를 찾음. 좋은 성능을 내는 구간으로 좁혀가며 파라미터를 탐색.
| 종류 | GridSearchCV | RandomizedSearchCV |
|---|---|---|
| 정의 | 완전히 탐색하여 하이퍼 파라미터를 검색 | 정해진 횟수 안에서 후보군로부터 조합을 랜덤하게 샘플링하여 최소의 오차를 찾는 모델이 하이퍼파라미터를 검색 |
| 장점 | 검증하고 싶은 하이퍼 파라미터의 수치를 지정하면 수치별 조합을 모두 검증하여 최적의 파라미터 검색의 정확도 향상 | 무작위 선정 후 조합을 검증. 빠른 속도로 최적의 파라미터 검색 가능. |
| 단점 | 후보군이 많을 수록 시간이 기하급수적으로 상승. 정확한 후보군 선정이 필요. | 후보군을 신중히 결정해야 하며, 랜덤한 조합들이 최적의 하이퍼 파라미터라는 보장이 없음. |
| 실행횟수 | 조합된 수만큼 실행 | K-fold * n_iter 수 만큼 실행. |
Hyper-parameter optimizers 공식 문서
Grid Search
from sklearn.model_selection import GridSearchCV
# CV = 몇개의 테스트 셋을 만들지를 설정
clf = GridSearchCV(model, parameters, n_jobs = -1, cv = 5)
clf.fit(X_train, y_train)
# GridSearch 결과 중 최적의 값을 보여주는 명령어
clf.best_estimator_
결과값
DecisionTreeClassifier(max_depth=3, max_features=0.9, random_state=42)
# Grid Serach 한 값을 DF형태로 변환하고, 가장 점수가 높은 파라미터를 찾기
pd.DataFrame(clf.cv_results_).sort_values("rank_test_score")
Randomized Search
from sklearn.model_selection import RandomizedSearchCV
# np.random.randint : 설정된 범위 내(3,10) 무작위로 (10)개 만큼의 int 값 출력. 소수는 출력X
# np.random.uniform : 설정된 범위 내(0.5, 1) 무작위로 (10)개 만큼 고유의 값 출력. 균등분포 함수
param_distributions = {"max_depth" : np.random.randint(3, 20, 10),
"max_features" : np.random.uniform(0.5, 1, 10)}
clfr = RandomizedSearchCV(model,
param_distributions=param_distributions,
n_iter = 10,
cv = 5,
scoring = "accuracy", n_jobs = -1,
random_state= 42)
# n_iter * cv = 50. 총 50번을 fit 함
clfr.fit(X_train, y_train)
clfr.best_estimator_
출력값
DecisionTreeClassifier(max_depth=4, max_features=0.6348746677804449,
random_state=42)
랜덤한 값이기 때문에 실행마다 다른 값이 나올 수 있음.
점수 측정하기
점수 평가 방법도 여러가지 존재
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
출력값
0.8622047244094488
from sklearn.metrics import classification_report
print(classification_report(y_test, y_predict))
출력값
precision recall f1-score support
0 0.88 0.92 0.90 165
1 0.83 0.76 0.80 89
accuracy 0.86 254
macro avg 0.85 0.84 0.85 254
weighted avg 0.86 0.86 0.86 254
