
CNN, 자연어 처리
⚠️ 해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료를 토대로 정리한 내용입니다.
🤔 이미지 데이터를 읽어오면 다차원 형태의 구조로 되어있는 np.array 형태로 되어있음에도 왜 다시 np.array로 만들어주었을까요?
리스트 안에는 np.array로 되어있더라도 여러 장의 이미지를 하나로 만들 때 ‘파이썬 리스트’에 작성해 주었다. 그래서 이미지 여러 장을 하나의 변수에 넣어주었을 때 해당 변수의 데이터 타입은 파이썬 리스트 구조이다.
Weather classification
정답 빈도수
# 예측값의 종류별 빈도수 입니다. 250~250 개 사이에 빈도수가 분포되어 있다.
lb.classes_
out:
array(['cloudy', 'foggy', 'rainy', 'shine', 'sunrise'], dtype='<U7')
# 예측값의 종류별 빈도수. 250-250개 사이에 빈도수가 분포
np.argmax(y_train, axis = 1)
out:
array([0, 4, 3, ..., 0, 4, 4], dtype=int64)
# 정답 인코딩이 제대로 되었는지 확인하고 클래스가 train, valid 균일하게 나뉘었는지 확인
# pd.Series 형태로 구성해준 이유는 np.array 형태이기 때문
# pandas 메서드를 사용하기 위해 series 형태로 변경
pd.Series(y_train_raw).value_counts(1)
out:
sunrise 0.233723
cloudy 0.200334
foggy 0.200334
rainy 0.199499
shine 0.166110
dtype: float64
pd.Series(y_valid_raw).value_counts(1)
out:
sunrise 0.233333
foggy 0.200000
cloudy 0.200000
rainy 0.200000
shine 0.166667
dtype: float64
층 구성 및 컴파일
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPool2D, Dropout, Flatten, Dense
# shape 열의 수가 5개 => 예측할 클래스의 수
y_train.shape
# input_shape를 확인해보자
input_shape = x_train[0].shape
input_shape
out:
(120, 120, 3)
model = Sequential()
# 입력층
model.add(Conv2D(filters=16, kernel_size=(3,3), activation='relu', input_shape= input_shape))
model.add(MaxPool2D(2,2))
model.add(Dropout(0.2))
# 1차원 형태로 변환하고 Fully-connected layer로 전달하기 위해서 Flatten()
model.add(Flatten())
model.add(Dense(units = 64, activation = 'relu'))
# 출력층
model.add(Dense(n_class, activation='softmax'))
# compile
model.compile(optimizer = "adam", loss = "categorical_crossentropy", metrics = "accuracy")
학습
from tensorflow.keras.callbacks import EarlyStopping
earlystop = EarlyStopping(monitor="val_accuracy", patience=5, verbose=1)
validation_split을 사용하지 않고 위에서 따로 validation_data를 나눠서 사용한 이유는 class를 statify 로 층화표집을 해주지 않으면 균일하게 학습이 되지 않는다. 멀티클래스일때 이렇게 데이터를 따로 균일하게 나눠서 학습시키지 않으면 성능이 낮게 나올 때가 많다.
history = model.fit(x_train, y_train, validation_data=(x_valid, y_valid),
epochs=20, callbacks=[earlystop])
History 확인
df_hist = pd.DataFrame(history.history)
df_hist.tail(3)
| loss | accuracy | val_loss | val_accuracy | |
|---|---|---|---|---|
| 14 | 0.128876 | 0.971619 | 0.460097 | 0.853333 |
| 15 | 0.136830 | 0.959933 | 0.545180 | 0.823333 |
| 16 | 0.113283 | 0.970785 | 0.488947 | 0.850000 |
16번에서 학습이 종료된 것을 확인할 수 있다.
df_hist[['loss','val_loss']].plot()
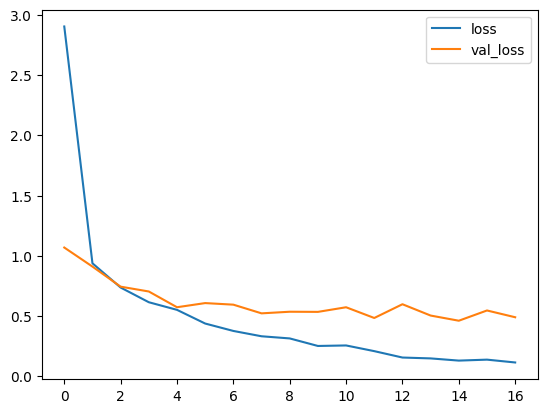
val_loss와 loss를 비교해본 결과, overfitting 현상이 일어나는 것을 확인할 수 있다.
예측
y_pred = model.predict(x_test)
y_pred[:5]
out:
array([[7.7497996e-03, 9.8399609e-01, 6.0868734e-03, 2.0637414e-03,
1.0362823e-04],
[7.6899529e-01, 3.0639231e-02, 1.8297195e-01, 1.7156394e-02,
2.3719769e-04],
[1.6711195e-01, 4.2176589e-02, 1.3776097e-02, 7.7679491e-01,
1.4050411e-04],
[2.9605310e-03, 1.6450478e-02, 5.7800547e-03, 9.7437513e-01,
4.3371419e-04],
[3.5579950e-02, 9.3897128e-01, 9.0040574e-03, 1.4856887e-02,
1.5878252e-03]], dtype=float32)
# 0번째 데이터의 각 클래스의 확률들을 다 합해주면 1이 나온다.
y_pred[0].sum()
out:
1.0000001
실제값과 예측값 비교
# test 데이터 불러오기
test = pd.read_csv(f"{root_dir}/test.csv")
y_test = test["labels"]
예측값과 실제값을 비교해본다.
y_predict = np.argmax(y_pred, axis=1) # 예측한 클래스 중 가장 높은 확률의 클래스를 반환
print(y_predict[:5])
print((y_test == y_predict).mean())
out:
[1 0 3 3 1]
0.8333333333333334
실제값과 예측값의 시각화
- 목적 : 전체 테스트 이미지를 시각화 후, 정답 유무를 확인해보도록 한다. 서브플롯으로 30개 이미지를 한번에 시각화를 하려면 row, col 을 구해서 해당 위치에 이미지를 넣어주어야 한다. 이미지를 여러 개 시각화 했을 때 알아서 위치에 들어가지 않기 때문에 어떤 위치다. 이미지의 주소를 지정해 준다고 생각하면 된다.
- 주의할 점 : test의 인코딩 값 순서와 train, valid 에서 사용한 순서가 맞는지 확인이 필요하다.(train의 0은 cloudy인데 test는 rain이 아닌지 확인해볼 필요가 있다.)
- 정답이 있는 test.csv 파일을 읽으면 파일이름과 정답이 있다. test.csv 순서대로 이미지를 가져와서 일단 먼저 시각화 하고 예측값과 비교해서 맞았는지 틀렸는지를 보도록 한다.
class_name = lb.classes_ # 레이블 제목을 지어주기 위해 변수 지정
fig, axes = plt.subplots(nrows=6, ncols=5, figsize=(20, 20))
for i, tcsv in test.iterrows():
col = i % 5
row = i // 5
Image_id = tcsv["Image_id"]
img_label = tcsv["labels"]
img = plt.imread(f"{root_dir}/alien_test/{Image_id}")
color = "red" # 예측이 잘못된 경우 제목을 빨간색으로 지정
if img_label == y_predict[i]:
color = "blue" # 예측이 정확한 경우 제목을 파란색으로 지정
axes[row, col].imshow(img)
axes[row, col].set_title(
f"test: {class_name[img_label]}, predict : {class_name[y_predict[i]]}", color=color)

정리
지금까지 CNN Explainer를 통해 Conv, Pooling 과정을 이미지로 이해해 보았다.
🤔 왜 완전밀집연결층을 첫 레이어 부터 사용하지 않고 합성곱 연산을 했을까요?
- 완전밀집연결층은 flatten해서 이미지를 입력해주는데 그러면 주변 이미지를 학습하지 못 하는 문제가 발생한다. 합성곱, 풀링 연산으로 특징을 학습하고 출력층에서 flatten해서 완전연결밀집층에 주입해 주고 결과를 출력한다.
- 기존에 사용했던 DNN에서 배웠던 개념을 확장해서 합성곱 이후 완전연결밀집층을 구성하는 형태로 진행해보았다.
- 이미지 전처리 도구는 matplotlib.pyplot 의 imread 를 통해 array 로 읽어올 수도 있고, PIL, OpenCV를 사용할 수도 있다.
- 이미지 증강 기법 등을 통해 이미지를 변환해서 사용할 수도 있다.
텍스트 분석과 자연어 처리
자연어 처리
개념
- 자연어(우리가 일상적에서 사용하는 언어)의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일
- 기계에게 인간의 언어를 이해시키는 인공지능의 한 분야
할 수 있는 일
텍스트 전처리
NLP에서의 test 표현 방법
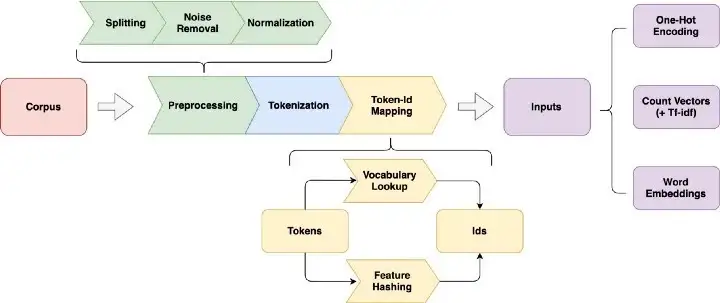
| 출처 : [An Overview for Text Representations in NLP | by jiawei hu | Towards Data Science](https://towardsdatascience.com/an-overview-for-text-representations-in-nlp-311253730af1) |
- 기계가 텍스트를 이해할 수 있도록 텍스트를 정제하여 신호와 소음을 구분
정규표현식
| 메타문자 | 기능 | 설명 |
|---|---|---|
| . | 문자 | 1개의 문자와 일치한다. 단일행 모드에서는 새줄 문자를 제외한다. |
| [ ] | 문자 클래스 | ”[“과 “]” 사이의 문자 중 하나를 선택한다. “¦”를 여러 개 쓴 것과 같은 의미이다. 예를 들면 [abc]d는 ad, bd, cd를 뜻한다. 또한, “-“ 기호와 함께 쓰면 범위를 지정할 수 있다. “[a-z]”는 a부터 z까지 중 하나, “[1-9]”는 1부터 9까지 중의 하나를 의미한다. |
| [^ ] | 부정 | 문자 클래스 안의 문자를 제외한 나머지를 선택한다. 예를 들면 [^abc]d는 ad, bd, cd는 포함하지 않고 ed, fd 등을 포함한다. [^a-z]는 알파벳 소문자로 시작하지 않는 모든 문자를 의미한다. |
| ^ | 처음 | 문자열이나 행의 처음을 의미한다. |
| $ | 끝 | 문자열이나 행의 끝을 의미한다. |
| ( ) | 하위식 | 여러 식을 하나로 묶을 수 있다. “abc¦adc”와 “a(b¦d)c”는 같은 의미를 가진다. |
| \n | 일치하는 n번째 패턴 | 일치하는 패턴들 중 n번째를 선택하며, 여기에서 n은 1에서 9 중 하나가 올 수 있다. |
| * | 0회 이상 | 0개 이상의 문자를 포함한다. “a*b”는 “b”, “ab”, “aab”, “aaab”를 포함한다. |
| {m, n} | m회 이상 n회 이하 | “a{1,3}b”는 “ab”, “aab”, “aaab”를 포함하지만, “b”나 “aaaab”는 포함하지 않는다. |
토큰화(Tokeniziation)
- 텍스트 조각을 토큰이라고 하는 더 작은 단위로 분리하는 방법
- 특정 문자(예. 띄어쓰기, 공백)으로 텍스트 데이터를 나눠주는 것
- NLTK, Spacy 도 대표적인 텍스트 전처리 도구이며, 토큰화, steming, lematization, 불용어 등의 기능을 제공
- 한글을 지원하지 않는 단점이 있음.
단어 벡터화 하기
분석할 문서
corpus = ["코로나 거리두기와 코로나 상생지원금 문의입니다.",
"지하철 운행시간과 지하철 요금 문의입니다.",
"지하철 승강장 문의입니다.",
"코로나 선별진료소 문의입니다.",
"버스 운행시간 문의입니다.",
"버스 터미널 위치 안내입니다.",
"코로나 거리두기 안내입니다.",
"택시 승강장 문의입니다."
]
Bag of Words
- 텍스트를 담는 가방. 단어의 순서들을 전혀 고려하지 않고 출현빈도에만 집중하는 텍스트 데이터의 수치화 표현 방법
- 가장 간단하지만 효과적이라 널리쓰이는 방법
- 단어의 순서가 완전히 무시된다는 단점
CountVectorizer
- 사이킷런에서 제공하는 BOW 기능
- 텍스트 문서 모음을 토큰 수의 행렬로 변환
- 단어의 출현빈도로 여러 문서들을 벡터화
# sklearn.feature_extraction.text의 CountVectorizer 를 통해 BOW 를 생성
from sklearn.feature_extraction.text import CountVectorizer
cvect = CountVectorizer()
cvect.fit_transform(corpus)
Fit, Transform, Fit_Transform의 차이점
- fit : 원시 문서에 있는 모든 토큰의 어휘사전 학습
- transform : 문서를 문서 용어 매트릭스로 변환 후 숫자 형태로 변경
- fit_transform : 어휘 사전을 배우고 문서 용어 매트릭스로 반환.
cvect = CountVectorizer()
dtm = cvect.fit_transform(corpus)
dtm
out:
<8x16 sparse matrix of type '<class 'numpy.int64'>'
with 27 stored elements in Compressed Sparse Row format>
# 변환된 cvect의 단어 내용 확인
vocab = cvect.get_feature_names_out()
vocab
out:
array(['거리두기', '거리두기와', '문의입니다', '버스', '상생지원금', '선별진료소', '승강장', '안내입니다',
'요금', '운행시간', '운행시간과', '위치', '지하철', '코로나', '택시', '터미널'],
dtype=object)
# 단어 사전 확인
cvect.vocabulary_
out:
{'코로나': 13,
'거리두기와': 1,
'상생지원금': 4,
'문의입니다': 2,
'지하철': 12,
'운행시간과': 10,
'요금': 8,
'승강장': 6,
'선별진료소': 5,
'버스': 3,
'운행시간': 9,
'터미널': 15,
'위치': 11,
'안내입니다': 7,
'거리두기': 0,
'택시': 14}
# 변환된 내용을 데이터프레임으로 변환하기
df_dtm = pd.DataFrame(dtm.toarray(), columns = vocab)
df_dtm.head()
| 거리두기 | 거리두기와 | 문의입니다 | 버스 | 상생지원금 | 선별진료소 | 승강장 | 안내입니다 | 요금 | 운행시간 | 운행시간과 | 위치 | 지하철 | 코로나 | 택시 | 터미널 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 2 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 4 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
# 전체 문서에서 단어 빈도의 합계
df_dtm.sum()
out:
거리두기 1
거리두기와 1
문의입니다 6
버스 2
상생지원금 1
선별진료소 1
승강장 2
안내입니다 2
요금 1
운행시간 1
운행시간과 1
위치 1
지하철 3
코로나 4
택시 1
터미널 1
dtype: int64
N-grams
- BOW 의 앞뒤 맥락을 고려하지 않는다는 단점을 해결하기 위해 사용
- 묶어서 사용하게 되면 앞뒤 맥락을 고려 가능
- (1,1) 이라면 1개의 토큰(기본값)을, (2,3)이라면 2~3개의 토큰을 사용
cvect = CountVectorizer(ngram_range=(1,2))
dtm = cvect.fit_transform(corpus)
vocab = cvect.get_feature_names_out()
df_dtm = pd.DataFrame(dtm.toarray(), columns = vocab)
df_dtm.head()
| 거리두기 | 거리두기 안내입니다 | 거리두기와 | 거리두기와 코로나 | 문의입니다 | 버스 | 버스 운행시간 | 버스 터미널 | 상생지원금 | 상생지원금 문의입니다 | … | 지하철 운행시간과 | 코로나 | 코로나 거리두기 | 코로나 거리두기와 | 코로나 상생지원금 | 코로나 선별진료소 | 택시 | 택시 승강장 | 터미널 | 터미널 위치 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | … | 0 | 2 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | … | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | … | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
df_dtm.sum()
out:
거리두기 1
거리두기 안내입니다 1
거리두기와 1
거리두기와 코로나 1
문의입니다 6
버스 2
버스 운행시간 1
버스 터미널 1
상생지원금 1
상생지원금 문의입니다 1
선별진료소 1
선별진료소 문의입니다 1
승강장 2
승강장 문의입니다 2
안내입니다 2
요금 1
요금 문의입니다 1
운행시간 1
운행시간 문의입니다 1
운행시간과 1
운행시간과 지하철 1
위치 1
위치 안내입니다 1
지하철 3
지하철 승강장 1
...
택시 1
택시 승강장 1
터미널 1
터미널 위치 1
dtype: int64
df_dtm = pd.DataFrame(dtm.toarray(), columns = vocab)
df_dtm.style.background_gradient()
df_dtm.head()
| 거리두기 | 거리두기 안내입니다 | 거리두기와 | 거리두기와 코로나 | 문의입니다 | 버스 | 버스 운행시간 | 버스 터미널 | 상생지원금 | 상생지원금 문의입니다 | … | 지하철 운행시간과 | 코로나 | 코로나 거리두기 | 코로나 거리두기와 | 코로나 상생지원금 | 코로나 선별진료소 | 택시 | 택시 승강장 | 터미널 | 터미널 위치 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | … | 0 | 2 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | … | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | … | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
df_dtm.sum()
out:
거리두기 1
거리두기 안내입니다 1
거리두기와 1
거리두기와 코로나 1
문의입니다 6
버스 2
버스 운행시간 1
버스 터미널 1
상생지원금 1
상생지원금 문의입니다 1
선별진료소 1
선별진료소 문의입니다 1
승강장 2
승강장 문의입니다 2
안내입니다 2
요금 1
요금 문의입니다 1
운행시간 1
운행시간 문의입니다 1
운행시간과 1
운행시간과 지하철 1
위치 1
위치 안내입니다 1
지하철 3
지하철 승강장 1
...
택시 1
택시 승강장 1
터미널 1
터미널 위치 1
dtype: int64
앞으로 진행할 실습에서 위 과정을 반복할 예정이기에 함수를 만들어주도록 하자.
# 모델을 받아 변환을 하고 문서 용어 행렬을 반환하는 함수를 만들어 재사용합니다.
def display_transform_dtm(cvect, corpus):
"""
모델을 받아 변환을 하고 문서 용어 행렬을 반환하는 함수
"""
dtm = cvect.fit_transform(corpus)
df_dtm = pd.DataFrame(dtm.toarray(), columns = cvect.get_feature_names_out())
return df_dtm.style.background_gradient()
잘 적용이 되는지 확인을 해보도록 한다.
cvect = CountVectorizer(ngram_range=(2,3))
display_transform_dtm(cvect, corpus)
| 거리두기 안내입니다 | 거리두기와 코로나 | 거리두기와 코로나 상생지원금 | 버스 운행시간 | 버스 운행시간 문의입니다 | 버스 터미널 | 버스 터미널 위치 | 상생지원금 문의입니다 | 선별진료소 문의입니다 | 승강장 문의입니다 | 요금 문의입니다 | 운행시간 문의입니다 | 운행시간과 지하철 | 운행시간과 지하철 요금 | 위치 안내입니다 | 지하철 승강장 | 지하철 승강장 문의입니다 | 지하철 요금 | 지하철 요금 문의입니다 | 지하철 운행시간과 | 지하철 운행시간과 지하철 | 코로나 거리두기 | 코로나 거리두기 안내입니다 | 코로나 거리두기와 | 코로나 거리두기와 코로나 | 코로나 상생지원금 | 코로나 상생지원금 문의입니다 | 코로나 선별진료소 | 코로나 선별진료소 문의입니다 | 택시 승강장 | 택시 승강장 문의입니다 | 터미널 위치 | 터미널 위치 안내입니다 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 6 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
min_df
- min_df는 문서 빈도(문서의 %에 있음)가 지정된 임계값보다 엄격하게 낮은 용어를 무시
- min_df를 0.1, 0.2로 설정한다면 10%, 20% 보다 많이 나타나는 용어만 학습
cvect = CountVectorizer(min_df = 2)
display_transform_dtm(cvect, corpus)
| 문의입니다 | 버스 | 승강장 | 안내입니다 | 지하철 | 코로나 | |
|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 2 |
| 1 | 1 | 0 | 0 | 0 | 2 | 0 |
| 2 | 1 | 0 | 1 | 0 | 1 | 0 |
| 3 | 1 | 0 | 0 | 0 | 0 | 1 |
| 4 | 1 | 1 | 0 | 0 | 0 | 0 |
| 5 | 0 | 1 | 0 | 1 | 0 | 0 |
| 6 | 0 | 0 | 0 | 1 | 0 | 1 |
| 7 | 1 | 0 | 1 | 0 | 0 | 0 |
max_df
- 어휘를 작성할 때 주어진 임계값보다 문서 빈도가 엄격히 높은 용어는 무시
- 빈번하게 등장하는 불용어 등을 제거하기에 좋음
- 예를 들어 코로나 관련 기사를 분석하면 90%에 ‘코로나’라는 용어가 등장할 수 있는데, 이 경우 max_df=0.89 로 비율을 설정하여 너무 빈번하게 등장하는 단어를 제외할 수 있음
# max_df=int : 빈도수를 의미
# max_df=float : 비율을 의미
cvect = CountVectorizer(max_df= 4)
display_transform_dtm(cvect, corpus)
| 거리두기 | 거리두기와 | 버스 | 상생지원금 | 선별진료소 | 승강장 | 안내입니다 | 요금 | 운행시간 | 운행시간과 | 위치 | 지하철 | 코로나 | 택시 | 터미널 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 2 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 4 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 6 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
max_features
- 벡터라이즈가 학습할 어휘의 양을 제한
- corpus중 빈도수가 가장 높은 순으로 해당 갯수만큼만 추출
cvect = CountVectorizer(max_features=10)
display_transform_dtm(cvect, corpus)
| 거리두기 | 거리두기와 | 문의입니다 | 버스 | 상생지원금 | 선별진료소 | 승강장 | 안내입니다 | 지하철 | 코로나 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 2 |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 4 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 6 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 7 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
불용어 stop_words
문장에 자주 등장하지만 “우리, 그, 그리고, 그래서” 등 관사, 전치사, 조사, 접속사 등의 단어로 문장 내에서 큰 의미를 갖지 않는 단어
stop_words=["코로나", "문의입니다", "터미널", "택시"]
# max_features 갯수만큼의 단어만 추출하기
cvect = CountVectorizer(stop_words= stop_words)
display_transform_dtm(cvect, corpus)
| 거리두기 | 거리두기와 | 버스 | 상생지원금 | 선별진료소 | 승강장 | 안내입니다 | 요금 | 운행시간 | 운행시간과 | 위치 | 지하철 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 2 |
| 2 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 5 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 6 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
analyzer
- 기본값=’word’
- 종류: word, char, char_wb
- 기능을 단어 n-그램으로 만들지 문자 n-그램으로 만들어야 하는지 여부를 정함.
- 옵션 ‘char_wb’는 단어 경계 내부의 텍스트에서만 문자 n-gram을 생성. 단어 가장자리의 n-gram은 공백으로 채워진다.
- 띄어쓰기가 제대로 되어 있지 않은 문자 등에 사용할 수 있다.
# analyzer='char_wb'
cvect = CountVectorizer(analyzer='char_wb', ngram_range= (4,6))
display_transform_dtm(cvect, corpus)
| 거리두 | 거리두기 | 거리두기 | 거리두기와 | 문의입 | 문의입니 | 문의입니다 | 버스 | 상생지 | 상생지원 | 상생지원금 | 선별진 | 선별진료 | 선별진료소 | 승강장 | 승강장 | 안내입 | 안내입니 | 안내입니다 | 요금 | 운행시 | 운행시간 | 운행시간 | 운행시간과 | 위치 | 지하철 | 지하철 | 코로나 | 코로나 | 택시 | 터미널 | 터미널 | 거리두기 | 거리두기 | 거리두기와 | 거리두기와 | 내입니다 | 내입니다. | 내입니다. | 니다. | 두기와 | 리두기 | 리두기와 | 리두기와 | 문의입니 | 문의입니다 | 문의입니다. | 별진료소 | 별진료소 | 상생지원 | 상생지원금 | 상생지원금 | 생지원금 | 생지원금 | 선별진료 | 선별진료소 | 선별진료소 | 승강장 | 시간과 | 안내입니 | 안내입니다 | 안내입니다. | 운행시간 | 운행시간 | 운행시간과 | 운행시간과 | 의입니다 | 의입니다. | 의입니다. | 입니다. | 입니다. | 지원금 | 지하철 | 진료소 | 코로나 | 터미널 | 행시간 | 행시간과 | 행시간과 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 2 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 1 |
| 2 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 6 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
cvect = CountVectorizer(analyzer='char', ngram_range= (4,6))
display_transform_dtm(cvect, corpus)
| 거리두 | 거리두기 | 거리두기 | 거리두기와 | 문의입 | 문의입니 | 문의입니다 | 상생지 | 상생지원 | 상생지원금 | 선별진 | 선별진료 | 선별진료소 | 승강장 | 승강장 | 승강장 문 | 안내입 | 안내입니 | 안내입니다 | 요금 | 요금 문 | 요금 문의 | 운행시 | 운행시간 | 운행시간 | 운행시간과 | 위치 | 위치 안 | 위치 안내 | 지하철 | 지하철 | 지하철 요 | 코로나 | 코로나 | 코로나 상 | 터미널 | 터미널 | 터미널 위 | 간 문의 | 간 문의입 | 간 문의입니 | 간과 지 | 간과 지하 | 간과 지하철 | 강장 문 | 강장 문의 | 강장 문의입 | 거리두기 | 거리두기 | 거리두기 안 | 거리두기와 | 거리두기와 | 과 지하 | 과 지하철 | 과 지하철 | 금 문의 | 금 문의입 | 금 문의입니 | 기 안내 | 기 안내입 | 기 안내입니 | 기와 코 | 기와 코로 | 기와 코로나 | 나 거리 | 나 거리두 | 나 거리두기 | 나 상생 | 나 상생지 | 나 상생지원 | 나 선별 | 나 선별진 | 나 선별진료 | 내입니다 | 내입니다. | 널 위치 | 널 위치 | 널 위치 안 | 두기 안 | 두기 안내 | 두기 안내입 | 두기와 | 두기와 코 | 두기와 코로 | 로나 거 | 로나 거리 | 로나 거리두 | 로나 상 | 로나 상생 | 로나 상생지 | 로나 선 | 로나 선별 | 로나 선별진 | 료소 문 | 료소 문의 | 료소 문의입 | 리두기 | 리두기 안 | 리두기 안내 | 리두기와 | 리두기와 | 리두기와 코 | 문의입니 | 문의입니다 | 문의입니다. | 미널 위 | 미널 위치 | 미널 위치 | 버스 운 | 버스 운행 | 버스 운행시 | 버스 터 | 버스 터미 | 버스 터미널 | 별진료소 | 별진료소 | 별진료소 문 | 상생지원 | 상생지원금 | 상생지원금 | 생지원금 | 생지원금 | 생지원금 문 | 선별진료 | 선별진료소 | 선별진료소 | 소 문의 | 소 문의입 | 소 문의입니 | 스 운행 | 스 운행시 | 스 운행시간 | 스 터미 | 스 터미널 | 스 터미널 | 승강장 | 승강장 문 | 승강장 문의 | 시 승강 | 시 승강장 | 시 승강장 | 시간 문 | 시간 문의 | 시간 문의입 | 시간과 | 시간과 지 | 시간과 지하 | 안내입니 | 안내입니다 | 안내입니다. | 와 코로 | 와 코로나 | 와 코로나 | 요금 문 | 요금 문의 | 요금 문의입 | 운행시간 | 운행시간 | 운행시간 문 | 운행시간과 | 운행시간과 | 원금 문 | 원금 문의 | 원금 문의입 | 위치 안 | 위치 안내 | 위치 안내입 | 의입니다 | 의입니다. | 입니다. | 장 문의 | 장 문의입 | 장 문의입니 | 지원금 | 지원금 문 | 지원금 문의 | 지하철 | 지하철 승 | 지하철 승강 | 지하철 요 | 지하철 요금 | 지하철 운 | 지하철 운행 | 진료소 | 진료소 문 | 진료소 문의 | 철 승강 | 철 승강장 | 철 승강장 | 철 요금 | 철 요금 | 철 요금 문 | 철 운행 | 철 운행시 | 철 운행시간 | 치 안내 | 치 안내입 | 치 안내입니 | 코로나 | 코로나 거 | 코로나 거리 | 코로나 상 | 코로나 상생 | 코로나 선 | 코로나 선별 | 택시 승 | 택시 승강 | 택시 승강장 | 터미널 | 터미널 위 | 터미널 위치 | 하철 승 | 하철 승강 | 하철 승강장 | 하철 요 | 하철 요금 | 하철 요금 | 하철 운 | 하철 운행 | 하철 운행시 | 행시간 | 행시간 문 | 행시간 문의 | 행시간과 | 행시간과 | 행시간과 지 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
| 2 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
TF-IDF
TF(단어 빈도, term frequency)는 특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값으로, 이 값이 높을수록 문서에서 중요하다고 생각할 수 있다. 하지만, 단어 자체가 문서군 내에서 자주 사용되는 경우, 이것은 그 단어가 흔하게 등장한다는 것을 의미한다. 이것을 DF(문서 빈도, document frequency)라고 하며, 이 값의 역수를 IDF(역문서 빈도, inverse document frequency)라고 한다. TF-IDF는 TF와 IDF를 곱한 값이다.
TfidfVectorizer
- 문서 모음을 TF-IDF 기능의 매트릭스로 변환
- TF-IDF 전체 문서에서는 자주 등장하지 않지만 특정 문서에서 자주 등장한다면 가중치 값이 높게 나오게 된다. 모든 문서에 자주 등장하는 값은 가중치가 낮게 나오게 된다.
tfidfvect = TfidfVectorizer()
tfidfvect.fit_transform(corpus)
display_transform_dtm(tfidfvect, corpus)
| 거리두기 | 거리두기와 | 문의입니다 | 버스 | 상생지원금 | 선별진료소 | 승강장 | 안내입니다 | 요금 | 운행시간 | 운행시간과 | 위치 | 지하철 | 코로나 | 택시 | 터미널 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000000 | 0.479919 | 0.239821 | 0.000000 | 0.479919 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.694148 | 0.000000 | 0.000000 |
| 1 | 0.000000 | 0.000000 | 0.222166 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.444589 | 0.000000 | 0.444589 | 0.000000 | 0.745200 | 0.000000 | 0.000000 | 0.000000 |
| 2 | 0.000000 | 0.000000 | 0.388500 | 0.000000 | 0.000000 | 0.000000 | 0.651563 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.651563 | 0.000000 | 0.000000 | 0.000000 |
| 3 | 0.000000 | 0.000000 | 0.375318 | 0.000000 | 0.000000 | 0.751070 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.543168 | 0.000000 | 0.000000 |
| 4 | 0.000000 | 0.000000 | 0.357659 | 0.599839 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.715732 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 5 | 0.000000 | 0.000000 | 0.000000 | 0.454195 | 0.000000 | 0.000000 | 0.000000 | 0.454195 | 0.000000 | 0.000000 | 0.000000 | 0.541948 | 0.000000 | 0.000000 | 0.000000 | 0.541948 |
| 6 | 0.670344 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.561801 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.484788 | 0.000000 | 0.000000 |
| 7 | 0.000000 | 0.000000 | 0.357659 | 0.000000 | 0.000000 | 0.000000 | 0.599839 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.715732 | 0.000000 |
