
CNN :이미지 분류
⚠️ 해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료를 토대로 정리한 내용입니다.
Tensorflow 이미지분류 튜토리얼
최초의 CNN : LeNet
라이브러리 호출
import matplotlib.pyplot as plt
import numpy as np
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
데이터세트 다운로드 및 탐색하기
이 튜토리얼에서는 약 3,700장의 꽃 사진 데이터세트를 사용한다. 데이터세트에는 클래스당 하나씩 5개의 하위 디렉터리가 존재한다.
flower_photo/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
결과값 : 3670
장미를 확인해본다.
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

PIL.Image.open(str(roses[1]))

튤립도 확인해본다.
tulips = list(data_dir.glob('tulips/*'))
PIL.Image.open(str(tulips[0]))

PIL.Image.open(str(tulips[1]))

🤔 튤립의 경우 이 이미지를 학습할 경우 어떤 문제가 발생할까?
튤립이 너무 많거나 튤립이 아닌 부분들이 많다. 이미지 데이터를 분류할 때도 전처리가 중요하다.
Keras 유틸리티를 사용하여 데이터 로드하기
- 유용한
tf.keras.utils.image_dataset_from_directory유틸리티를 사용하여 디스크에서 이러한 이미지를 로드 - 디스크의 이미지 디렉터리에서
tf.data.Dataset로 이동
데이터세트 만들기
몇 가지 매개변수를 정의한다.
# 배열에 다른값이 들어가면 계산이 불가하기 때문에 값을 고정
batch_size = 32
img_height = 180
img_width = 180
PIL , OpenCV 등을 내부에서 사용하고 있는데 우리가 포토샵에서 이미지 사이즈 줄이는 것 처럼 이미지 사이즈를 조정해준다. 이미지 사이즈 크기에 따른 장단점이 존재한다.
- 작은 사이즈 : 이미지가 왜곡되거나 손실될 수도 있지만 계산량이 줄어들기 때문에 빠르게 학습한다.
- 큰 사이즈 : 작은 이미지를 늘리면 왜곡될 수도 있지만 더 자세히 학습하기 때문에 성능이 좋을 수 있지만, 계산이 오래 걸린다.
Train과 Validation set을 만들어준다.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
결과값:
Found 3670 files belonging to 5 classes.
Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
결과값 :
Found 3670 files belonging to 5 classes.
Using 734 files for validation.
클래스의 이름을 확인해본다.
class_names = train_ds.class_names
print(class_names)
데이터 시각화하기
처음 9개의 이미지를 확인해본다.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

성능을 높이도록 데이터세트 구성하기
Dataset.cache()는 첫 epoch 동안 디스크에서 이미지를 로드한 후 이미지를 메모리에 유지한다. 이렇게 하면 모델을 훈련하는 동안 데이터세트가 병목 상태가 되지 않는다. 데이터세트가 너무 커서 메모리에 맞지 않는 경우, 이 메서드를 사용하여 성능이 높은 온디스크 캐시를 생성할 수도 있다.Dataset.prefetch는 훈련하는 동안 데이터 전처리 및 모델 실행을 중첩시킵니다.
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
데이터 표준화하기
# 0~1 사이의 값으로 만들어주기
normalization_layer = layers.Rescaling(1./255)
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
미리 데이터 표준화를 시켜주었지만, 모델에서도 표준화기능을 사용할 수 있다.
기본 Keras 모델
모델 만들기
num_classes = len(class_names)
model = Sequential([
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(filters = 16, kernel_size = 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(filters = 32, kernel_size = 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(filters = 64, kernel_size = 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
모델 컴파일하기
tf.keras.optimizers.Adam옵티마이저와 tf.keras.losses.SparseCategoricalCrossentropy손실 함수를 선택한다.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
모델 훈련하기
epochs=10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
훈련 결과 시각화
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
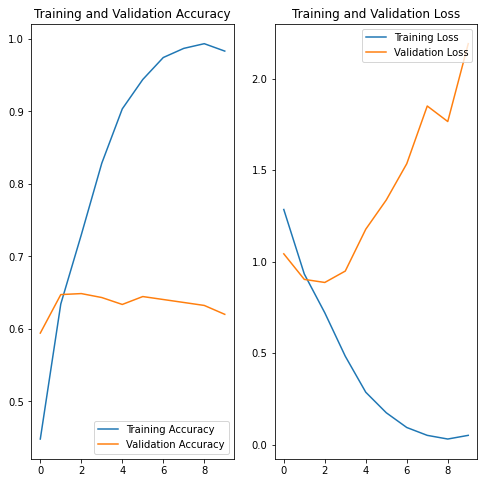
Validation Loss를 보면 현재 모델은 오버피팅이 일어난 것을 확인할 수 있다. 한 가지 이유로 단정하기는 어렵지만 가장 성능이 안 좋게 나온 중점적인 이유를 찾는다면 이미지 전처리가 제대로 되어있지 않아서 일어난 것으로 판단된다. 훈련 예제가 적을 때 모델은 새로운 예제에서 모델의 성능에 부정적인 영향을 미치는 정도까지 훈련 예제의 노이즈나 원치 않는 세부까지 학습하게 된다. 이는 모델이 새 데이터세트에서 일반화하는 데 어려움이 있음을 의미한다. 훈련 과정에서 과대적합을 막는 여러 가지 방법들이 있고, 이 튜토리얼에서는 데이터 증강을 사용하고 모델에 드롭아웃을 추가한다.
데이터 증강
- 학습 데이터가 적어서 과대적합이 우려될 때, 기준 데이터로부터 이미지를 랜덤하게 생성하여 데이터의 수를 증강한다.
- Keras 전처리 레이어
tf.keras.layers.RandomFlip,tf.keras.layers.RandomRotation,tf.keras.layers.RandomZoom을 사용하여 데이터 증강을 구현한다. 데이터를 접고, 돌리고, 당긴다.

-
출처 : [Data Augmentation for Object Detection Kaggle](https://www.kaggle.com/code/ankursingh12/data-augmentation-for-object-detection/notebook)
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.1),
]
)
동일한 이미지에 데이터 증강을 여러 번 적용하여 몇 가지 증강 예제를 시각화하자. 실행할 때마다 다른 이미지의 데이터를 가져올 수 있다.
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")

Dropout
과대적합을 줄이는 또 다른 기술은 네트워크에 dropout 정규화를 도입하는 것이다.
드롭아웃을 레이어에 적용하면, 훈련 프로세스 중에 레이어에서 여러 출력 단위가 무작위로 드롭아웃한다.(활성화를 0으로 설정). 드롭아웃은 0.1, 0.2, 0.4 등의 형식으로 소수를 입력 값으로 사용하며, 이는 적용된 레이어에서 출력 단위의 10%, 20% 또는 40%를 임의로 제거하는 것을 의미한다.
증강 이미지를 사용하여 훈련하기 전에 tf.keras.layers.Dropout을 사용하여 새로운 신경망을 생성한다. Dropout을 적용한 모델을 만들어주도록 한다.
model = Sequential([
data_augmentation,
layers.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes, name="outputs")
])
모델 컴파일 및 훈련하기
# 컴파일
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 모델 요약
model.summary()
결과값:
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential_1 (Sequential) (None, 180, 180, 3) 0
rescaling_2 (Rescaling) (None, 180, 180, 3) 0
conv2d_3 (Conv2D) (None, 180, 180, 16) 448
max_pooling2d_3 (MaxPooling (None, 90, 90, 16) 0
2D)
conv2d_4 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_4 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_5 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_5 (MaxPooling (None, 22, 22, 64) 0
2D)
dropout (Dropout) (None, 22, 22, 64) 0
flatten_1 (Flatten) (None, 30976) 0
dense_2 (Dense) (None, 128) 3965056
outputs (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
# 학습
epochs = 15
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
훈련 결과 시각화하기
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
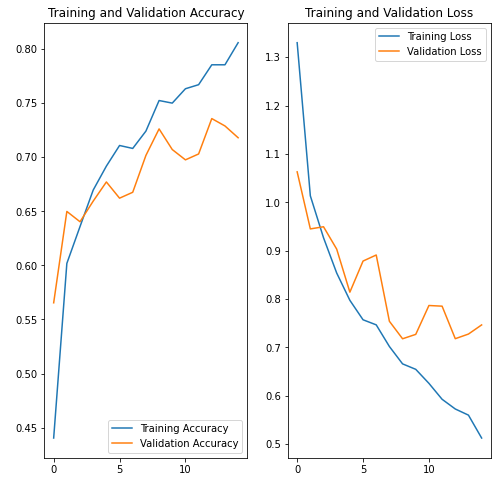
이미지 전처리와 dropout을 추가한 결과 오버피팅이 일어나지 않은 것을 확인하였다. 꽃 이미지에는 노이즈가 많기 때문에 Accuracy 가 데이터 증강, Dropout을 했을 때 0.6대에서 0.7정도로 정확도가 높아진 것을 확인할 수 있다.
말라리아 셀 이미지
- 말라리아 스크리너 연구 활동의 분할된 세포의 얇은 혈액 도말 슬라이드 이미지
- 리소스가 제한된 지역에서 현미경 전문가의 부담을 줄이고 진단 정확도를 개선하기 위해 NLM(National Library of Medicine)의 일부인 Lister Hill National Center for Biomedical Communications(LHNCBC)의 연구원들은 모바일 애플리케이션을 개발
- 방글라데시 치타공 의과대학 병원에서 150명의 P. falciparum 감염자와 50명의 건강한 환자의 Giemsa 염색 얇은 혈액 도말 슬라이드를 수집하고 사진을 촬영
- 적혈구를 감지하고 분할하기 위해 레벨 세트 기반 알고리즘을 적용
# 이미지 다운로드
!wget https://data.lhncbc.nlm.nih.gov/public/Malaria/cell_images.zip
# images 폴더에 다운로드 받은 파일 압축 해제하기
!unzip cell_images.zip
# 상대경로는 통해 cell_images 폴더를 로드.
# 실습하고 있는 파일과 같은 위치에 images 폴더가 위치해있어야 폴더명만을 통해 경로를 읽을 수 있다.
# images 경로를 root로 하위 디렉토리를 dirs로 해당 경로에 있는 모든 파일을 files로 볼 수 있다.
import os
for dirpath, dirnames, filenames in os.walk('cell_images/'):
print(dirpath, dirnames)
# glob은 패턴(유닉스 셸이 사용하는 규칙)을 사용하여 파일을 검색하는 모듈로
# 현재 디렉터리와 하위 디렉터리의 모든 텍스트파일을 찾아서 출력한다.
#'./cell_images/*/*.png' 파일 목록을 출력해보자.
import glob
paths = glob.glob("./cell_images/*/*.png")
paths[:5]
RGB 색상
matplotlib을 통한 이미지 데이터의 RGB값 이해
상대경로를 사용해서 실습 경로와 같은 위치에 있는 images 폴더에 있는 이미지를 불러온다. 그리고 이미지 데이터를 배열 형태로 만든다. 이 때, matplotlib의 imread 기능을 사용하면 이미지를 배열형태로 가져올 수 있다.
matplotlib.pyplot 을 plt 라는 별칭으로 불러와서 pyplot의 imread로 파일을 읽어온다. 읽어 온 파일을 출력해 보면 3개의 채널을 갖는 이미지 배열임을 확인할 수 있다. 이 때, 행과 열의 수는 이미지의 세로와 가로 크기가 된다. 이렇게 불러온 이미지의 R, G, B 각 채널별 배열값을 확인해보자.
import matplotlib.pyplot as plt
img = plt.imread(paths[0])
img.shape
결과값 : (124, 163, 3)
plt.imshow(img)
plt.axis("off")

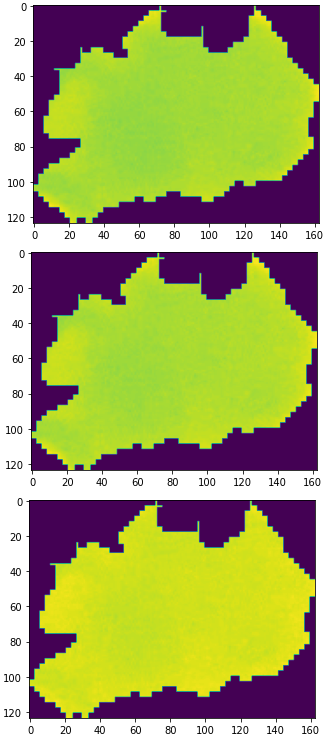
이미지는 3개의 채널로 구성되어 있다. 파이썬은 인덱스 번호가 0번부터 시작하기 때문에 0, 1, 2 으로 각각 R,G,B 채널에 접근할 수 있다.
# n 번 인덱스 채널
plt.imshow(img[:,:,0]) # R
plt.imshow(img[:,:,1]) # G
plt.imshow(img[:,:,2]) # B
이미지 처리 도구
PIL(Python Imaging Library) Pillow
Python Imaging Library(PIL)은 파이썬 인터프리터에 다양한 이미지 파일 형식을 지원하고 강력한 이미지 처리와 그래픽 기능을 제공하는 자유-오픈 소스 소프트웨어 라이브러리이다. PIL 이미지 작업을 위한 표준 절차를 제공하고 있으며, 다음과 같은 것이있다.
- 픽셀 단위의 조작
- 마스킹 및 투명도 제어
- 흐림, 윤곽 보정 다듬어 윤곽 검출 등의 이미지 필터
- 선명하게, 밝기 보정, 명암 보정, 색 보정 등의 화상 조정
- 이미지에 텍스트 추가
- 기타 여러가지
# 이미지 파일을 매번 지정하기 번거롭지 않게 변수에 담아 재사용
cell_img = paths[1]
cell_img
# Image.open 으로 이미지를 로드
from PIL import Image, ImageFilter
original = Image.open(cell_img)
original
# resize 로 이미지 사이즈를 변경
original.resize((150, 150))
# save 로 이미지를 저장
original.save("original.png")
Open CV
OpenCV(Open Source Computer Vision)은 실시간 컴퓨터 비전을 목적으로 한 프로그래밍 라이브러리. 실시간 이미지 프로세싱에 중점을 둔 라이브러리이다.
Image Processing in OpenCV
- OpenCV: Image Processing in OpenCV
- Changing Colorspaces - Learn to change images between different color spaces. Plus learn to track a colored object in a video.
- Geometric Transformations of Images - Learn to apply different geometric transformations to images like rotation, translation etc.
- Image Thresholding - Learn to convert images to binary images using global thresholding, Adaptive thresholding, Otsu’s binarization etc
- Smoothing Images - Learn to blur the images, filter the images with custom kernels etc.
- Morphological Transformations - Learn about morphological transformations like Erosion, Dilation, Opening, Closing etc
- Image Gradients - Learn to find image gradients, edges etc.
- Canny Edge Detection - Learn to find edges with Canny Edge Detection
- Image Pyramids - Learn about image pyramids and how to use them for image blending
- Contours in OpenCV - All about Contours in OpenCV
- Histograms in OpenCV - All about histograms in OpenCV
- Image Transforms in OpenCV - Meet different Image Transforms in OpenCV like Fourier Transform, Cosine Transform etc.
- Template Matching - Learn to search for an object in an image using Template Matching
- Hough Line Transform - Learn to detect lines in an image
- Hough Circle Transform - Learn to detect circles in an image
- Image Segmentation with Watershed Algorithm
- Learn to segment images with watershed segmentation
- Interactive Foreground Extraction using GrabCut Algorithm
- Learn to extract foreground with GrabCut algorithm
현재 내용 정리
말라리아 혈액도말 이미지 분류 실습을 진행하기 위해 이미지를 불러오는 방법과 이미지 전처리를 어떻게 해주는가에 대해 학습하였다. 다음으로는 TF 공식문서의 이미지 분류를 다른 이미지를 사용해서 응용해보는 것을 목표로 한다.
일부 이미지 미리보기
import glob
upics = glob.glob('./cell_images/Uninfected/*.png')
apics = glob.glob('./cell_images/Parasitized/*.png')
len(upics), upics[0], len(apics), apics[0]
# upics
# matplotlib 으로 불러온 방법
upics_0 = upics[0]
upics_0_img = plt.imread(upics_0)
plt.imshow(upics_0_img)

# apics
# matplotlib 으로 불러온 방법
apics_0 = apics[0]
apics_0_img = plt.imread(apics_0)
plt.imshow(apics_0_img)
# cv2 로 Uninfected 시각화
import cv2
plt.figure(figsize=(8, 8))
labels = "Uninfected"
for i, images in enumerate(upics[:9]):
ax = plt.subplot(3, 3, i + 1)
img = cv2.imread(images)
plt.imshow(img)
plt.title(f'{labels} {img.shape}')
plt.axis("off")

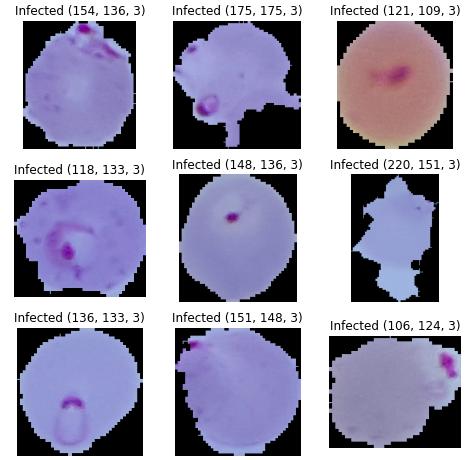
# cv2 로 Infected 시각화
plt.figure(figsize=(8, 8))
labels = "Infected"
for i, images in enumerate(apics[:9]):
ax = plt.subplot(3, 3, i + 1)
img = cv2.imread(images)
plt.imshow(img)
plt.title(f'{labels} {img.shape}')
plt.axis("off")
데이터셋 나누기
Keras의 ImageDataGenerater로 이미지를 로드하고 전처리를 진행한다. Keras의 ImageDataGenerator는 다음과 같은 이미지 변환 유형을 지원한다.
공간 레벨 변형
- Flip : 상하, 좌우 반전
- Rotation : 회전
- Shift : 이동
- Zoom : 확대, 축소
- Shear : 눕히기
픽셀 레벨 변형
- Bright : 밝기 조정
- Channel Shift : RGB 값 변경
- ZCA Whitening : Whitening 효과
# ImageDataGenerator를 통해 이미지를 로드하고 전처리
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# validation_split 값을 통해 학습:검증 비율을 8:2 로 나누기
datagen = ImageDataGenerator(rescale=1/255.0, validation_split=0.2)
이미지 사이즈 설정
width = 32
height = 32
🤔 원본이미지와 비교했을 때 권장하는 이미지 크기는 따로 없나요?
상황에 따라 다르다. 장비가 연산을 많이 지원할 수 있다면 원본 사이즈를 사용하고 장비 계산이 너무 오래 걸린다면 줄여주는 것이 좋다. 이미지의 사이즈는 임의대로 해도 상관없지만, 딥러닝의 경우 Network 모델의 입력 사이즈와 반드시 동일하게 해줘야 한다. 참고로 CNN의 대표적인 모델들은 네트워크 입력사이즈가 224 * 224인 경우가 많다.
학습 및 검증 세트
flow_from_directory를 통해 이미지를 불러오고 training 데이터셋을 생성한다. class_mode에는 이진분류(감염 여부 판단)이기 때문에 binary를 넣어준다.
# class_mode: One of "categorical", "binary", "sparse","input", or None. Default: "categorical".
# subset: Subset of data ("training" or "validation")
trainDatagen = datagen.flow_from_directory(directory = 'cell_images/',
target_size = (height, width),
class_mode = 'binary',
batch_size = 64,
subset='training')
trainDatagen.num_classes
결과값 : 2
trainDatagen.classes
결과값 : array([0, 0, 0, ..., 1, 1, 1], dtype=int32)
Validation set을 생성하도록고 한다.
# validation 데이터셋을 생성
valDatagen = datagen.flow_from_directory(directory = 'cell_images/',
target_size =(height, width),
class_mode = 'binary',
batch_size = 64,
subset='validation')
# 0 : 감염, 1 : 감염 안 됨
valDatagen.class_indices
결과값 : {'Parasitized': 0, 'Uninfected': 1}
요약
- 주제: 말라리아 혈액도말 이미지 분류 실습
- 목적: TF공식 문서의 이미지 분류를 다른 이미지를 사용해서 응용
- 이미지 데이터 불러오기 wget을 사용하면 온라인 URL 에 있는 파일을 불러올 수 있다. 논문(혈액도말 이미지로 말라리아 감염여부를 판단하는 논문)에 사용한 데이터셋을 불러왔다.
plt.imread와cv2(OpenCV)의imread를 통해 array 형태로 데이터를 불러와서 시각화를 해서 감염된 이미지와 아닌 이미지를 비교하였다.TF.keras의 전처리 도구를 사용해서 train, valid set을 나눠주었다 ⇒ 레이블값을 폴더명으로 생성
앞으로 할 내용은 CNN 레이어를 구성, 컴파일 하고 학습하고 정확도(Accuray) 성능을 비교해볼 예정
모델 구성 및 학습과 예측
레이어 구성
model = Sequential()
# 입력층
model.add(Conv2D(filters=16, kernel_size=(3,3), padding='valid',
activation='relu', input_shape=(height, width, 3)))
model.add(MaxPool2D(pool_size=(2,2), strides=1))
model.add(Conv2D(filters=16, kernel_size=(3,3), padding='same',
activation='relu'))
model.add(Conv2D(filters=16, kernel_size=(3,3), padding='same',
activation='relu'))
model.add(MaxPool2D(pool_size=(2,2), strides=1))
model.add(Conv2D(filters=16, kernel_size=(3,3), padding='same',
activation='relu'))
model.add(Conv2D(filters=16, kernel_size=(3,3), padding='same',
activation='relu'))
model.add(MaxPool2D(pool_size=(2,2), strides=1))
# Fully-connected layer
model.add(Flatten())
model.add(Dense(units = 64, activation = "relu"))
model.add(Dropout(0.2))
model.add(Dense(units = 32, activation = "relu"))
model.add(Dropout(0.2))
# 출력층
model.add(Dense(1, activation='sigmoid'))
💡 Padding 옵션의 vaild와 same의 차이점
conv2d층의 padding 매개변수의 기본값은 "vaild"로 커널이 인풋 이미지 밖으로 슬라이딩 하지 않습니다. 이런 경우 출력은 입력보다 작아지게 된다.
padding 매개변수를 "same"으로 해줄 경우 출력 크기가 입력값과 동일해지도록 입력 이미지 주위에 0 픽셀이 패딩된다.
🤔 비선형 활성화 함수(Activation function)가 없이 여러 개의 층을 쌓을 경우?
비선형 활성화 함수가 없이 여러 개의 층을 쌓을 경우 기본 선형 활성화 함수를 사용하게 되므로 하나의 층을 가진 선형 모델과 성능이 비슷하다. 은닉층에 비선형 활성화 함수를 추가하지 않으면 계산 자원과 시간을 낭비하는 결과를 초래하고 수치적으로 불안정성이 높아지게 된다. 이런 현상은 밀집 층 뿐만 아니라 아까 말한 합성곱 층과 같이 다른 종류의 층에도 적용되게 된다. (예를 들어 “비선형 활성화 함수 없이” 두 개의 합성곱 층을 쌓는 경우 그냥 많은 커널을 가진 하나의 conv2d 층을 사용하는 것과 수학적으로 동일하기 때문에 비효율 적으로 합성곱 신경망을 만드는 것과 다름없다!)
모델 요약
# summary
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_15 (Conv2D) (None, 30, 30, 16) 448
max_pooling2d_9 (MaxPooling (None, 29, 29, 16) 0
2D)
conv2d_16 (Conv2D) (None, 29, 29, 16) 2320
conv2d_17 (Conv2D) (None, 29, 29, 16) 2320
max_pooling2d_10 (MaxPoolin (None, 28, 28, 16) 0
g2D)
conv2d_18 (Conv2D) (None, 28, 28, 16) 2320
conv2d_19 (Conv2D) (None, 28, 28, 16) 2320
max_pooling2d_11 (MaxPoolin (None, 27, 27, 16) 0
g2D)
flatten_3 (Flatten) (None, 11664) 0
dense_5 (Dense) (None, 64) 746560
dropout_2 (Dropout) (None, 64) 0
dense_6 (Dense) (None, 32) 2080
dropout_3 (Dropout) (None, 32) 0
dense_7 (Dense) (None, 1) 33
=================================================================
Total params: 758,401
Trainable params: 758,401
Non-trainable params: 0
_________________________________________________________________
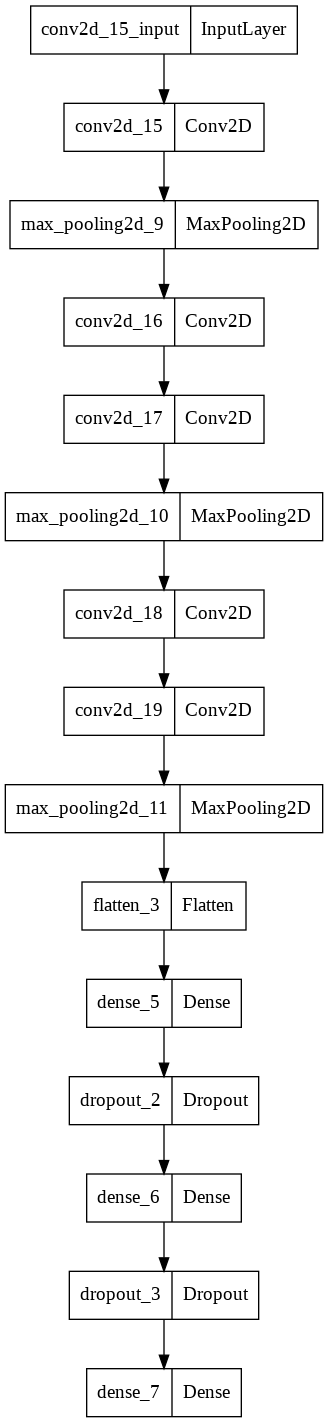
# tensorflow.keras.utils의 plot_model 을 통한 레이어 시각화
from tensorflow.keras.utils import plot_model
plot_model(model)
컴파일
# model.compile
# 옵티마이저 'adam'
# 손실함수 이진분류
# 측정지표 'accuracy'
model.compile(optimizer = "adam",
loss = "binary_crossentropy", metrics = "accuracy")
학습
early_stop = EarlyStopping(monitor='val_loss', patience=10)
# fit
history = model.fit(trainDatagen, validation_data = valDatagen, epochs = 30, verbose = 2, callbacks = early_stop)
# history
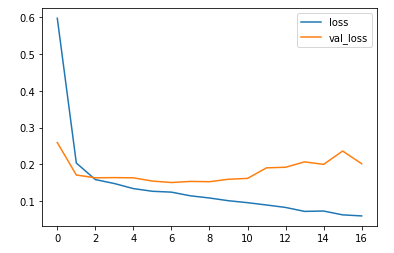
df_hist = pd.DataFrame(history.history)
df_hist.tail(3)
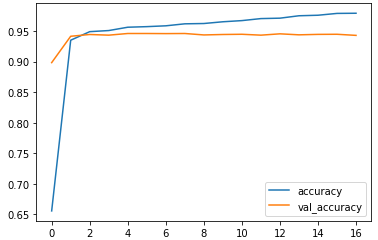
| loss | accuracy | val_loss | val_accuracy |
|---|---|---|---|
| 14 | 0.072565 | 0.976007 | 0.199645 |
| 15 | 0.062142 | 0.979000 | 0.235941 |
| 16 | 0.059259 | 0.979272 | 0.201430 |
df_hist[["loss", "val_loss"]].plot()
df_hist[["accuracy", "val_accuracy"]].plot()
💡 입력 데이터 종류와 이에 맞는 네트워크 구조에 대해 정리
- 벡터 데이터(시간이나 순서가 상관 없음): MLP (밀집층)
- 이미지 데이터(흑백 또는 컬러): 2D 합성곱 신경망
- 스펙트로그램 오디오 데이터: 2D 합성곱 신경망이나 순환 신경망
- 텍스트 데이터: 1D 합성곱 신경망이나 순환 신경망
- 시계열 데이터(시간이나 순서가 중요함): 1D 합성곱 신경망이나 순환 신경망
- 볼륨 데이터(예: 3D 의료 이미지): 3D 합성곱 신경망
- 비디오 데이터(이미지의 시퀀스): 3D 합성곱 신경망(모션 효과를 감지해야 하는 경우) 또는 특성 추출을 위해 프레임 별로 적용한 2D 합성곱 신경망과 만들어진 특성 시퀀스를 처리하기 위한 RNN이나 1D 합성곱 신경망의 조합
지금은 이 중에 2D 합성곱 신경망을 통한 이미지 데이터 학습모델에 대해 진행을 하고 있다.
💡 합성곱 신경망에 대한 정리
합성곱 층은 입력받은 텐서에서 공간적으로 다른 위치에 기하학적 변환을 적용하여 국부적인 공간 패턴을 찾는다. 이런 방식은 이동 불변성을 가진 표현을 만들기 때문에 합성곱 층을 매우 데이터 효율적으로 만들고 모듈화시킨다. 위와 같은 아이디어는 어떤 차원 공간에도 적용할 수 있기 때문에 1D(시퀀스), 2D(이미지나 이미지가 아니자만 사운드 스펙트로그램처럼 비슷한 표현), 3D(볼륨 데이터) 등에 적용할 수 있다. 텐서플로우에서는 conv1d 층으로 시퀀스를 처리하고, conv2d층으로 이미지를 처리하고, conv3d 층으로 볼륨 데이터를 처리할 수 있다. 합성곱 신경망은 합성곱 층과 풀링 층을 쌓아서 구성하게 된다. 풀링 층은 공간적으로 데이터를 다운샘플링하고 이는 특성 개수가 늘어나게되면 후속층이 합성곱 신경망의 입력 이미지에서 더 많은 공간을 바라보도록 특성 맵의 크기를 적절하게 유지시킨다. 합성곱 신경망은 공간적인 특성 맵을 벡터로 바꾸기 위해 종종 flatten층과 전역 풀링 층으로 끝나기도 한다. 그리고 일련의 밀집층(MLP)로 처리하여 분류나 회귀 출력을 만들게 된다.
