
CNN : 말라리아 감염 구분, 날씨 사진 분류
⚠️ 해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료를 토대로 정리한 내용입니다.
Tensorflow 이미지분류 튜토리얼
🤔Stride를 크게 설정하면?
용량이 줄어들고 학습속도가 빨라지게 된다. 하지만, 자세히 학습하지 못하기 때문에 언더피팅이 일어날 수 있다.
🤔 이미지 데이터 증강 시 주의해야 할 사항은?
증강할 때 train set에만 해준다. 왜냐하면 현실세계 문제를 푼다고 가정했을 때 이미지가 들어왔을 때 증강하지 않은 이미지로 판단하기 때문에 train에만 사용한다. 크롭이나 확대 시 노이즈에 적용하게 되면 학습과 예측이 어려워지므로 주의한다. 또한, 증강기법을 사용했을 경우 이미지의 의미가 변형될 수 있는 경우(숫자 6과 9의 반전, 신호등과 같은 색상의 중요도 등)가 있기 때문에 주의를 요한다.
ILSVRC 이미지 인식 경진대회
- 카테고리 1,000개와 이미지 100만개를 대상으로 이미지에 대한 정확도를 겨루는 대회(2010년 시작)
🤔 CNN모델 학습 중에 메모리 오류가 났을 경우?
- 이미지 사이즈 줄이기
- 레이어 줄이기
- 필터수 줄이기
- 배치(한번에 다 불러오지 않고 나눠서 불러오게) 사이즈를 줄이기
말라리아 셀 이미지
해당과정은 지난 내용과 중복된 내용들을 가지고 있기 때문에, 앞선 과정들은 생략하도록 하겠다.
이미지 사이즈 설정
- 이미지의 사이즈가 불규칙하면 학습을 할 수 없기 때문에 리사이즈할 크기를 지정한다.
# 원본 이미지는 100~200 내외
width = 32
height = 32
학습과 검증 세트 나누기
# flow_from_directory 를 통해 이미지를 로드
# 학습 세트
trainDatagen = datagen.flow_from_directory(directory = 'cell_images/',
target_size = (height, width),
class_mode = 'binary',
batch_size = 64,
subset='training')
# 검증 세트
valDatagen = datagen.flow_from_directory(directory = 'cell_images/',
target_size =(height, width),
class_mode = 'binary',
batch_size = 64,
subset='validation')
레이어 설정
Module: tf.keras.applications
- 유명한 모델 아키텍처로 학습해서 찾아놓은 가중치를 사용한다.
⇒ 유명 모델 아키텍처를 사용하는 것.
이 중에서 우리는 VGG16 모델을 사용할 것이다(리소스가 충분히 받쳐준다면 VGG19를 사용해도 좋다). 전이학습을 사용할 예정이다.
# tensorflow.keras.applications.vgg16에서 16개의 층을 사용하는 VGG16 모델을 불러온다.
from tensorflow.keras.applications.vgg16 import VGG16
# include_top : VGG16에 있는 출력층을 의미한다. True로 사용할 경우,
# VGG16출력층을 사용한다. 현재 예제에서는 출력층을 따로 지정했기 때문에
# False로 지정한다.
vgg = VGG16(include_top=False, weights='imagenet', input_shape = (height, width, 3))
model = Sequential()
model.add(vgg)
model.add(Flatten())
model.add(Dense(1, activation = "sigmoid"))
이후, 모델 학습과 예측은 기존과 동일하게 진행해주도록 한다.
Weather Classification
라이브러리 로드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import random
import os
import tqdm as tqdm
import cv2
import os
필자는 Google의 Colab 환경에서 작업하고 있으며, 구글드라이브에 받은 데이터를 저장해놨다. 코랩 환경에서 내 구글드라이브에 접근하기 위해 라이브러리를 로드한다.
from google.colab import drive
drive.mount('/content/drive')
이미지 로드
# 예측에 사용할 정답값을 폴더명을 사용해서 만들기
import os
root_dir = "/content/drive/MyDrive/dataset"
image_label = os.listdir(root_dir)
image_label.remove("test.csv")
image_label
결과값 : ['cloudy', 'rainy', 'alien_test', 'foggy', 'shine', 'sunrise']
일부 이미지 미리보기
import glob
fig, axes = plt.subplots(nrows=1, ncols=len(image_label), figsize=(20, 5))
for i, img_label in enumerate(image_label):
wfiles = glob.glob(f"{root_dir}/{img_label}/*")
wfiles = sorted(wfiles)
# print(wfiles[0])
img = plt.imread(wfiles[0])
axes[i].imshow(img)
axes[i].set_title(img_label)

이미지 데이터셋 만들기
def img_read_resize(img_path):
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (120, 120))
return img
전체 이미지 파일을 읽어서 list 에 담아주는 함수를 만들어주도록 하자. 특정 날씨 폴더의 전체 이미지를 읽어온다. 그 다음, 반복문을 통해서 이미지를 하나씩 순회하며 img_read 로 배열 형태로 변경된 이미지를 읽어온다. 그리고 img_files 리스트에 읽어온 이미지를 append로 하나씩 추가하고, 반복문 순회가 끝나면 img_files리스트를 반환하도록 하자.
# root_dir = "/content/drive/MyDrive/dataset"
# image_label = os.listdir(root_dir)
# image_label.remove("test.csv")
# image_label
def img_folder_read(img_label):
"""
목적 : 폴더별 이미지 읽어오는 함수
특정 폴더에 있는 이미지를
array 형태로 읽어와서 리스트에 담아주는 함수
형식에 맞지 않는 이미지는 제외하고 가져오도록 try, except 를 사용
"""
img_files = []
labels = []
wfiles = glob.glob(f"{root_dir}/{img_label}/*")
wfiles = sorted(wfiles)
for w_img in wfiles:
try:
img_files.append(img_read_resize(w_img))
labels.append(img_label)
except:
continue
return img_files, labels
img_label = "shine"
img_files, labels = img_folder_read(img_label)
len(img_files), len(labels), img_files[0].shape, labels[0]
결과값 : (249, 249, (120, 120, 3), 'shine')
이제 test와 train set을 나눠주도록 하자. 나누는 기준은 경진대회에서 기준인 “alien_test”내애 있는 파일들을 기준으로 나눠줄 예정이다.
x_train_img = []
x_test_img = []
y_train_img = []
y_test_img = []
# tqdm 을 통해 이미지를 읽어오는 상태를 표시
for img_label in tqdm.tqdm(image_label):
x_temp, y_temp = img_folder_read(img_label)
if img_label == "alien_test":
# x, y값 만들기
x_test_img.extend(x_temp)
y_test_img.extend(y_temp)
else:
x_train_img.extend(x_temp)
y_train_img.extend(y_temp)
len(x_train_img), len(y_train_img), len(x_test_img), len(y_test_img)
결과값 :
100%|██████████| 6/6 [00:14<00:00, 2.39s/it]
(1498, 1498, 30, 30)
🤔 append()와 extend()의 차이점?
append는 통째로 추가하고, extend는 풀어서 추가한다. 예시로 사탕을 다른 봉지에 담을 때 봉지 째 담을 경우가 append, 봉지의 사탕을 낱개로 따로 옮겨 담을 경우가 extend라고 이해하면 편하다.
나눈 값의 사진과 레이블이 잘 출력되는지를 확인해보자.
# 사진과 레이블 제목을 출력하는 함수
def train_img(x):
plt.imshow(x_train_img[x])
plt.title(y_train_img[x])
def test_img(y):
plt.imshow(x_test_img[y])
plt.title(y_test_img[y])
train_img(0)

test_img(0)
x, y값 np.array 형식으로 만들기
# x_array
# y_array
x_train_arr = np.array(x_train_img)
y_train_arr = np.array(y_train_img)
x_test_arr = np.array(x_test_img)
y_test_arr = np.array(y_test_img)
x_train_arr.shape, y_train_arr.shape, x_test_arr.shape, y_test_arr.shape
결과값 : ((1498, 120, 120, 3), (1498,), (30, 120, 120, 3), (30,))
Train, valid 나누기
# train_test_split
# class가 균일하게 나눠지지 않아 학습이 불균형해지는 문제가 있다.
# valid 데이터를 직접 넣어주면 조금 더 학습이 좋아진다.
# x_train_raw, x_valid_raw, y_train_raw, y_valid_raw
from sklearn.model_selection import train_test_split
x_train_raw, x_valid_raw, y_train_raw, y_valid_raw = train_test_split(
x_train_arr, y_train_arr, test_size = 0.2, stratify = y_train_arr, random_state = 42)
x_train_raw.shape, x_valid_raw.shape, y_train_raw.shape, y_valid_raw.shape
결과값 : ((1198, 120, 120, 3), (300, 120, 120, 3), (1198,), (300,))
이미지 데이터 정규화
x_train = x_train_raw/255
x_valid = x_valid_raw/255
x_test = x_test_arr/255
x_train[0].max(), x_valid[0].max(), x_test.max()
결과값 : (1.0, 1.0, 1.0)
🤔 이미지 정규화할 때 왜 255로 나누는가?
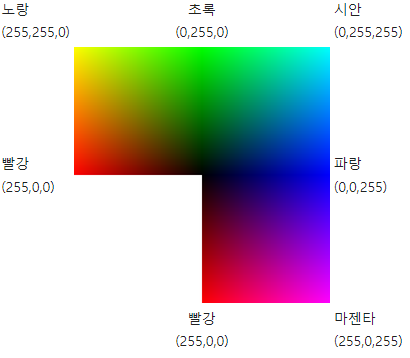
결론부터 말하면 RGB 최대값이 255이다. 따라서 최대 255의 값을 가진 RGB값을 255로 나눠서 0~1 사이로 정규화 시켜준다. 현대의 대부분 모니터의 최대 지원 색 심도는 24비트다(물론 더 많이 지원하는 모니터 들도 많이 나왔다). 즉, 각 픽셀은 2^24(~16.7M)의 색상을 표시할 수 있게 되어있고 24비트 값을 각각 R, G, B 세개의 색상으로 나누자면 24비트 / 3이므로 각 채널의 폭은 8비트를 가지게 된다. 채널당 8비트라는것을 고려할때 0 ~ 255 (256개)의 숫자 값만 인코딩 할 수 있게 되는 것이 이치에 맞는다.
정답 One-Hot-Encoding
LabelBinarizer 를 사용하여 ‘cloudy’, ‘shine’, ‘sunrise’, ‘rainy’, ‘foggy’ 형태의 분류를 숫자로 변경한다. y_test는 정답값 비교를 할 예정이고 학습에 사용하지 않기 때문에 인코딩 하지 않아도 된다.
from sklearn.preprocessing import LabelBinarizer
lb = LabelBinarizer()
lb.fit(y_train_raw)
print(lb.classes_)
y_train = lb.transform(y_train_raw)
y_valid = lb.transform(y_valid_raw)
y_train.shape, y_valid.shape
결과값:
['cloudy' 'foggy' 'rainy' 'shine' 'sunrise']
((1198, 5), (300, 5))
💡 지금까지의 과정들 정리!
- 목표 train, valid, test set 에 대한 X, y값 만들기!
- label 별로 각 폴더의 파일의 목록을 읽어온다.
- 이미지와 label 리스트를 만들어서 넣어준다.
- test는 폴더가 따로 존재하기 때문에 이미지를 불러올 때 test여부를 체크해서 train, test 를 먼저 만들어준다.
- np.array 형태로 변환한다.
- train 으로 train, valid 를 나누어 준다.
- train, valid, test 를 만들어 준다.(진행 예정)
😵💫 이미지 파일을 array 로 만드는 과정은 어렵기 보다는 복잡하다! 때문에 복잡한 문제들이 대체적으로 어렵게 느껴진다. 하지만, 불행히도 현업을 할 때도 업무가 복잡하다. 고로, 과정을 이해하는게 중요하다. 복잡한 문제들은 작은 단위로 나눠서 차근차근 해결하는 것을 추천한다.
