
딥러닝 입문
⚠️ 해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료를 토대로 정리한 내용입니다.
신경망이란 무엇인가?
- Dropout : 과대적합(과적합, 오버피팅)을 방지하기 위해 일부 노드를 제거하고 사용하는 것.
텐서플로 2.0 시작하기: 초보자용
Tensorflow
# Tensorflow 호출
import tensorflow as tf
데이터세트(MNIST 데이터세트) 로드하기
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 255로 나누는 이유는 0~255 사이의 값을 가진 변수들을 0~1 사이로 스케일링 하기 위함
# tf에서는 X는 소문자를 사용
x_train, x_test = x_train / 255.0, x_test / 255.0
# ndim : 차원의 수
x_train.ndim, x_test.ndim
결과값 : (3, 3)
0번째 파일을 시각화해보도록 하자.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
idx = 0
# DataFrame에 수치에 따라서 색을 입힌다.
display(pd.DataFrame(x_train[idx]).style.background_gradient())
sns.heatmap(x_train[idx], cmap = "gray")
plt.title(f"label : [idx]")
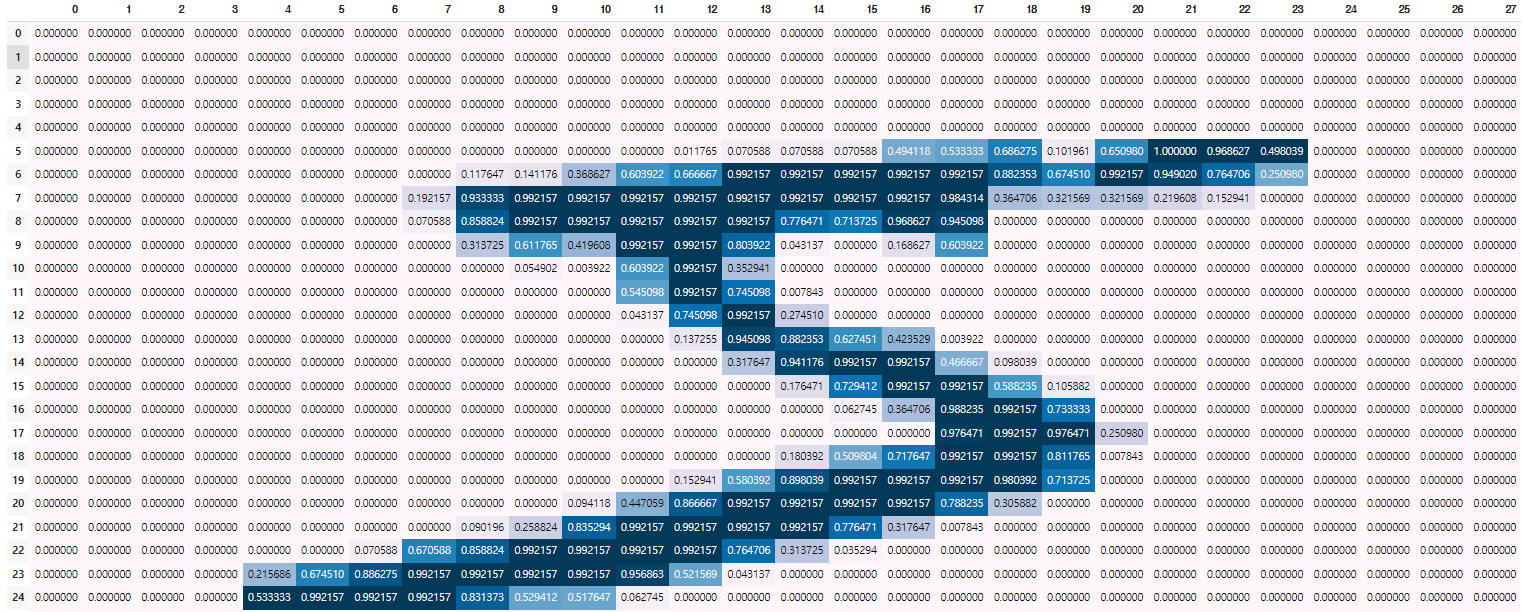
숫자 5라는 이미지가 들어가있다.
🤔 MNIST 손글씨 이미지 데이터셋은 왜 만들었을까?
우편번호를 읽어내가 위해서 만들어지게 되었다. MNIST 데이터베이스 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
머신 러닝 모델 빌드하기
층을 차례대로 쌓아 tf.keras.Sequential모델을 만든다. 훈련에 사용할 옵티마이저(optimizer)와 손실 함수를 선택한다.
model = tf.keras.models.Sequential([
# Flatten : n차원의 데이터를 1차원으로 만들어준다.
# 여기서는 28*28의 2차원 데이터를 1차원으로 만들어준다.
tf.keras.layers.Flatten(input_shape=(28, 28)),
# output = activation(dot(input, kernel) + bias)
# 출력 = 활성화함수(행렬곱(input, kernel) + 편향)
# 128 : hidden layer의 unit(nod)의 개수
tf.keras.layers.Dense(128, activation='relu'),
# dropout(0.2) : unit의 20%는 사용하지 않는다.
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# optimizer : 오차가 최소가 되는 지점을 찾기 위한 함수. 기울기, 방향, learning rate를 고려
# optimizer는 대부분 adam을 사용. 모르면 adam을 써도 무방함.
model.compile(optimizer='adam',
# loss : 손실율을 측정
loss='sparse_categorical_crossentropy',
# metrics : 평가지표
metrics=['accuracy'])
| output에 대한 자세한 설명은 아래 이미지를 보면 된다. (출처 : [But what is a neural network? | Chapter 1, Deep learning - YouTube](https://www.youtube.com/watch?v=aircAruvnKk&ab_channel=3Blue1Brown)) |

이제 빌드한 모델로 예측을 진행하도록 한다.
predictions = model(x_train[:1]).numpy()
predictions
결과값 :
array([[0.09023821, 0.16924651, 0.09414785, 0.09464978, 0.11364367,
0.04734194, 0.06211803, 0.08623113, 0.0585422 , 0.18384069]],
dtype=float32)
import numpy as np
# softmax 는 다 더했을 때 1이 된다.
# softmax 는 각 클래스의 확률을 출력한다.
smax = tf.nn.softmax(predictions).numpy()
smax, f"softmax는 다 더했을 때 1이 됩니다. : {np.sum(smax)}",
# np.argmax() : ()안에 가장 큰 값의 인덱스를 반환해줌
f"정답 클래스 : {np.argmax(smax)}"
결과값:
(array([[0.09893701, 0.10707095, 0.09932458, 0.09937444, 0.10127999,
0.09478272, 0.09619364, 0.09854135, 0.09585028, 0.10864502]],
dtype=float32), 'softmax는 다 더했을 때 1이 됩니다. : 1.0', '정답 클래스 : 9')
예측한 값을 손실함수를 통해서 오차가 얼마나 발생하는지를 평가해보도록 한다.
# loss : 모델의 예측값과 실제값이 얼마나 차이가 있는지를 평가하는 손실함수
# 분류는 주로 크로스엔트로피를 사용한다.
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
loss_fn(y_train[:1], predictions).numpy()
결과값 : 2.356168
모델 훈련 및 평가하기
모델을 훈련하고 평가를 진행하도록 한다.
# 여러 번 학습을 하면 loss가 점점 줄어들게 된다.
# 학습을 하면서 weigth, bias 값을 업데이트 한다.
# epochs : 해당 모델을 몇번 훈련할지를 정한다.
model.fit(x_train, y_train, epochs=5)
결과값:
Epoch 1/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2978 - accuracy: 0.9123
Epoch 2/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.1448 - accuracy: 0.9567
Epoch 3/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.1075 - accuracy: 0.9675
Epoch 4/5
1875/1875 [==============================] - 6s 3ms/step - loss: 0.0892 - accuracy: 0.9722
Epoch 5/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.0761 - accuracy: 0.9754
<keras.callbacks.History at 0x7f9e2344b090>
tf에서 학습은 누적이 된다. loss를 줄이고 accuracy를 높이기 위해서 한번 더 진행해보도록 한다.
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)
결과값:
Epoch 1/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0659 - accuracy: 0.9789
Epoch 2/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0585 - accuracy: 0.9811
Epoch 3/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0533 - accuracy: 0.9826
Epoch 4/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0496 - accuracy: 0.9837
Epoch 5/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0444 - accuracy: 0.9856
313/313 - 1s - loss: 0.0704 - accuracy: 0.9809 - 609ms/epoch - 2ms/step
[0.070419542491436, 0.98089998960495]
모델이 확률을 반환하도록 하려면 다음과 같이 훈련된 모델을 래핑하고 여기에 소프트맥스를 첨부할 수 있다.
probability_model = tf.keras.Sequential([
model,
tf.keras.layers.Softmax()
])
y_pred = probability_model(x_test[:5])
y_pred
결과값:
<tf.Tensor: shape=(5, 10), dtype=float32, numpy=
array([[0.08533826, 0.08533826, 0.08533835, 0.08534597, 0.08533826,
0.08533826, 0.08533826, 0.23194528, 0.08533826, 0.08534084],
[0.08533677, 0.08533696, 0.23196885, 0.08533677, 0.08533677,
0.08533677, 0.08533677, 0.08533677, 0.08533677, 0.08533677],
[0.08533906, 0.23193273, 0.08534102, 0.08533909, 0.08533926,
0.08533906, 0.08533906, 0.08535206, 0.08533961, 0.08533906],
[0.2319687 , 0.08533678, 0.08533681, 0.08533678, 0.08533678,
0.08533678, 0.08533701, 0.08533679, 0.08533678, 0.08533678],
[0.08536852, 0.08536851, 0.08536855, 0.08536851, 0.23146583,
0.08536851, 0.08536852, 0.08537116, 0.08536851, 0.08558335]],
dtype=float32)>
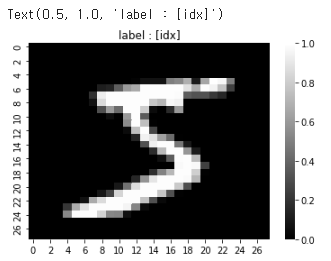
print(np.argmax(y_pred[0]))
sns.heatmap(x_test[0], cmap = "gray")
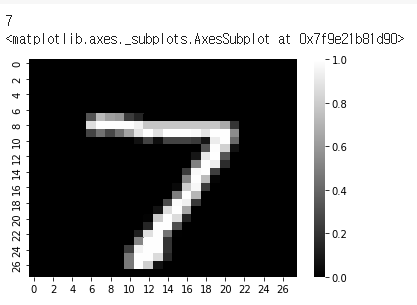
기본 분류 : 의류 이미지 분류
- 운동화나 셔츠 같은 옷 이미지를 분류하는 신경망 모델을 훈련
- 완전한 텐서플로(TensorFlow) 프로그램을 빠르게 살펴 보도록 한다.
- 상세한 내용을 이해하지 못하더라고 괜찮다.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
결과값 : 2.9.2
패션 MNIST 데이터셋 임포트하기
- 10개의 범주(category)와 70,000개의 흑백 이미지로 구성된 패션 MNIST 데이터셋을 사용
- 이미지는 해상도(28x28 픽셀)가 낮고 다음처럼 개별 옷 품목을 나타낸다.
# 데이터 로드
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
train_images와train_labels배열은 모델 학습에 사용되는 훈련 세트test_images와test_labels배열은 모델 테스트에 사용되는 테스트 세트
# 독립 변수 설정
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
데이터 탐색
train_images.shape
결과값 : (60000, 28, 28)
len(train_labels)
결과값 : 60000
train_labels
결과값 : array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
레이블은 0 과 9 사이의 정수임을 확인하였다.
test_images.shape
결과값 : (10000, 28, 28)
len(test_labels)
결과값 : 10000
데이터 전처리
# min~max 범위 확인
train_images[0].min(), train_images[0].max()
결과값 : (0, 255)
# class_names가 무엇인지 확인
class_names[train_labels[0]]
결과값 : Ankle boot
이미지를 시각화해보도록 하자.
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
# 0~1로 정규화 해주기
train_images = train_images / 255.0
test_images = test_images / 255.0
훈련 세트에서 처음 25개 이미지와 그 아래 클래스 이름을 출력해 보죠. 데이터 포맷이 올바른지 확인하고 네트워크 구성과 훈련할 준비를 마칩니다.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

모델 구성
층 구성
# units = Nod = Neuron
# 입력 - 은닉층 - 출력층으로 구성된 네트워크 모델
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
모델 컴파일
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
모델 훈련
훈련은 기존 방법과 동일하게 진행된다.
model.fit(train_images, train_labels, epochs=10)
이후 내용들은 위 과정과 상이하기에 생략하도록 한다. 자세한 내용은 여기에서 확인할 수 있다.
요약
- 다른 모델에 적용한다면 층 구성을 어떻게 할것인가? ⇒입력-은닉-출력층으로 구성
- 예측하고자 하는 값이 분류(이진, 멀티클래스), 회귀인지에 따라 출력층 구성, loss 설정이 달라진다.
- 분류, 회귀에 따라 측정 지표 정하기
- 활성화함수는 relu를 사용, optimizer 로는 adam을 사용하면 baseline 정도의 스코어가 나온다.
- fit을 할 때 epoch를 통해 여러 번 학습을 진행하는데 이 때, epoch수가 많을 수록 대체적으로 좋은 성능을 내지만 과대적합(오버피팅)이 될 수도 있다.
- epoch수가 너무 적다면 과소적합(언더피팅)이 될 수도 있다.
Optimizer - 데이터와 손실함수를 기반으로 모델이 업데이트 되는 방식
- 모델이 인식하는 데이터와 해당 손실 함수를 기반으로 모델이 업데이트되는 방식을 뜻함
경사하강법(Gradient Descent)
손실함수의 손실이 낮아찌는 쪽으로 가중치를 주며 움직이며 최솟값을 찾는 방법
확률적 경사하강법
- 경사하강법과 다르게 랜덤하게 추출한 일부 데이터에 대해 가중치를 조절하며 최적의 해를 찾음.
- 속도가 더 빠르나, 정확도가 낮음(local minima 문제)
극소(local minima) 문제
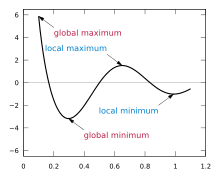
- 출처 : 극값 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
- 옵티마이저가 최소점(global minimum)을 찾아야하는데 최소점이 아닌 극소점(local minimum)을 찾는 문제가 발생.
Optimizer
- 손실함수를 최소화하는 방향으로 가중치를 갱신하는 알고리즘
- 등산으로 비유
- Gradient Descent : 내려가는 방향을 찾는 방법
- Optimizer : 효율적(시간, 성능 고려)으로 탐색
- 참고할만 자료 : 자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다. (slideshare.net)
Pima TF classification
과거 당뇨병 데이터셋을 이용해서 TF를 사용할 것이다.(차후 업로드를 진행할 예정) 따라서 사전 데이터 탐색 과정은 생략하도록 한다.
데이터셋 나누기
# label_name
label_name = 'Outcome'
# X, y 만들기
feature_names = df.columns.drop(label_name)
X = df[feature_names]
y = df[label_name]
# sklearn.model_selection 으로 데이터셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, stratify = y, random_state = 42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
결과값 : ((614, 8), (154, 8), (614,), (154,))
# tensorflow 를 tf로 불러오기
import tensorflow as tf
활성화 함수 activations
활성화 함수는 많은 종류들이 있다. 어떤 종류들이 있는지를 확인해보자.
print(dir(tf.keras.activations)[10:]
결과값 : ['deserialize', 'elu', 'exponential', 'gelu', 'get', 'hard_sigmoid', 'linear', 'relu', 'selu', 'serialize', 'sigmoid', 'softmax', 'softplus', 'softsign', 'swish', 'tanh']
각 활성화 함수들이 어떻게 동작하는지 시각화를 통해서 알아보자.
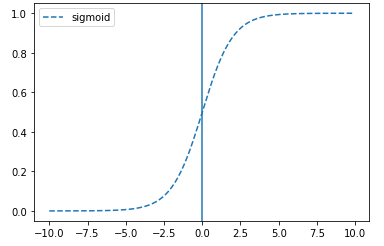
# tf.keras.activations.sigmoid(x)
# x축은 원래 값을 y축은 sigmoid 함수를 통과시킨 값입니다.
plt.plot(x, tf.keras.activations.sigmoid(x), linestyle='--', label="sigmoid")
plt.axvline(0)
plt.legend()
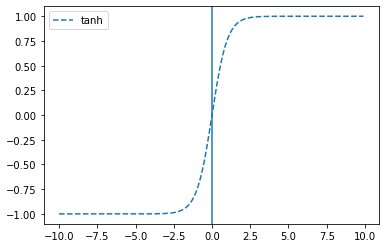
# tanh
plt.plot(x, tf.keras.activations.tanh(x), linestyle='--', label="tanh")
plt.axvline(0)
plt.legend()
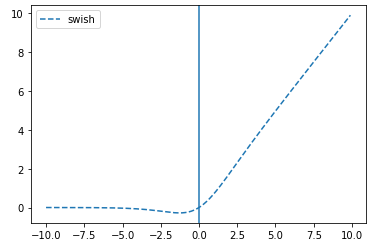
# swish
plt.plot(x, tf.keras.activations.swish(x), linestyle='--', label="swish")
plt.axvline(0)
plt.legend()
# relu
plt.plot(x, tf.keras.activations.relu(x), linestyle='--', label="relu")
plt.axvline(0)
plt.legend()
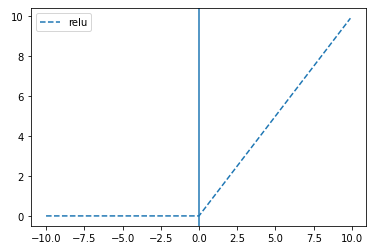
딥러닝 레이어 만들기
모델 빌딩
# 입력데이터 수 구하기
input_shape = X.shape[1]
input_shape
결과값 : 8
# tf.keras.models.Sequential 로 입력-히든-출력(sigmoid) 레이어로 구성
model = tf.keras.models.Sequential([
# 해당 데이터는 1차원으로 flatten을 해줄 필요가 없기 때문에(이진분류) Dense를 적용시켜준다.
tf.keras.layers.Dense(128, input_shape=[input_shape]),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])
모델 컴파일
model.compile(optimizer='adam',
# 이진 분류이기 때문에 loss funciton은 binary_crossentropy를 사용한다.
loss='binary_crossentropy',
metrics=['accuracy'])
학습
- 배치(batch): 모델 학습에 한 번에 입력할 데이터셋
- 에폭(epoch): 모델 학습시 전체 데이터를 학습한 횟수
- 스텝(step): (모델 학습의 경우) 하나의 배치를 학습한 횟수
# 학습과정을 출력하는 과정을 '.'으로 표현해주는 함수이다.
class PrintDot(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
# val_loss 기준으로 값의 향상이 없다면 멈추게 한다.
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
from re import VERBOSE
# 학습하기
# callbacks=[early_stop, PrintDot()]
history = model.fit(X_train, y_train, epochs = 100, validation_split=0.2, callbacks = [early_stop, PrintDot()], verbose
# 학습결과의 history 값을 가져와서 비교하기 위해 데이터프레임으로 변환
df_hist = pd.DataFrame(history.history)
df_hist.tail()
| loss | accuracy | val_loss | val_accuracy | |
|---|---|---|---|---|
| 11 | 0.553114 | 0.729124 | 0.501547 | 0.813008 |
| 12 | 0.531260 | 0.731161 | 0.521571 | 0.723577 |
| 13 | 0.546065 | 0.723014 | 0.497894 | 0.747967 |
| 14 | 0.539685 | 0.716904 | 0.520553 | 0.715447 |
| 15 | 0.565220 | 0.698574 | 0.507848 | 0.756098 |
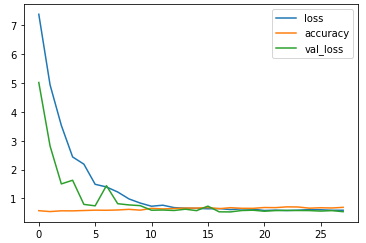
해당 학습같은 경우, 15번만에 학습이 종료되었다. 여러가지 이유가 있지만, 우선 early_stop에서 patience를 너무 적게 준 것으로 판단된다. 100정도 부여한다면 학습을 더 늘릴 것으로 예상할 수 있으나 과대적합 발생을 유의해야 한다.
학습결과 시각화
# loss, accuracy, val_loss 값 시각화
df_hist[["loss", "accuracy", "val_loss"]].plot()

{kind=link}