
IDF, 연합뉴스 타이틀 주제 분류
⚠️ 해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료를 토대로 정리한 내용입니다.
IDF
IDF 값은 문서군의 성격에 따라 결정된다. 예를 들어 ‘원자’라는 낱말은 일반적인 문서들 사이에서는 잘 나오지 않기 때문에 IDF 값이 높아지고 문서의 핵심어가 될 수 있지만, 원자에 대한 문서를 모아놓은 문서군의 경우 이 낱말은 상투어가 되어 각 문서들을 세분화하여 구분할 수 있는 다른 낱말들이 높은 가중치를 얻게 된다.
# 하나의 문서에만 나타나는 토큰은 idf 가중치가 높다.
# 적게 나타난 토큰이라도 모든 문서에도 있는 토큰은 idf가 낮다.
idf = tfidfvect.idf_
idf
out:
array([2.5040774 , 2.5040774 , 1.25131443, 2.09861229, 2.5040774 ,
2.5040774 , 2.09861229, 2.09861229, 2.5040774 , 2.5040774 ,
2.5040774 , 2.5040774 , 2.09861229, 1.81093022, 2.5040774 ,
2.5040774 ])
# 사전만들기
# dict, zip 을 사용하여 피처명과 idf 값을 딕셔너리 형태로 만든다.
vocab = tfidfvect.get_feature_names_out()
vocab
out:
array(['거리두기', '거리두기와', '문의입니다', '버스', '상생지원금', '선별진료소', '승강장', '안내입니다',
'요금', '운행시간', '운행시간과', '위치', '지하철', '코로나', '택시', '터미널'],
dtype=object)
idf_dict = dict(zip(vocab, idf))
idf_dict
out:
{'거리두기': 2.504077396776274,
'거리두기와': 2.504077396776274,
'문의입니다': 1.251314428280906,
'버스': 2.09861228866811,
'상생지원금': 2.504077396776274,
'선별진료소': 2.504077396776274,
'승강장': 2.09861228866811,
'안내입니다': 2.09861228866811,
'요금': 2.504077396776274,
'운행시간': 2.504077396776274,
'운행시간과': 2.504077396776274,
'위치': 2.504077396776274,
'지하철': 2.09861228866811,
'코로나': 1.8109302162163288,
'택시': 2.504077396776274,
'터미널': 2.504077396776274}
tfidfvect = TfidfVectorizer(analyzer='char_wb', ngram_range=(2, 3), max_df=1.0, min_df=1, stop_words=["코로나"])
display_transform_dtm(tfidfvect, corpus)
-
out
거 거리 문 문의 버 버스 상 상생 선 선별 승 승강 안 안내 요 요금 운 운행 위 위치 지 지하 코 코로 택 택시 터 터미 . 간 간과 간과 강장 강장 거리 거리두 과 금 기 기와 기와 나 내입 내입니 널 니다 니다. 다. 다. 두기 두기 두기와 로나 로나 료소 료소 리두 리두기 문의 문의입 미널 미널 버스 버스 별진 별진료 상생 상생지 생지 생지원 선별 선별진 소 스 승강 승강장 시 시간 시간 시간과 안내 안내입 와 요금 요금 운행 운행시 원금 원금 위치 위치 의입 의입니 입니 입니다 장 지원 지원금 지하 지하철 진료 진료소 철 치 코로 코로나 택시 택시 터미 터미널 하철 하철 행시 행시간 0 0.138007 0.138007 0.082288 0.082288 0.000000 0.000000 0.164671 0.164671 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.238178 0.238178 0.000000 0.000000 0.000000 0.000000 0.065761 0.000000 0.000000 0.000000 0.000000 0.000000 0.138007 0.138007 0.000000 0.138007 0.000000 0.164671 0.164671 0.238178 0.000000 0.000000 0.000000 0.065761 0.065761 0.065761 0.065761 0.138007 0.000000 0.164671 0.238178 0.238178 0.000000 0.000000 0.138007 0.138007 0.082288 0.082288 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.164671 0.164671 0.164671 0.164671 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.164671 0.000000 0.000000 0.000000 0.000000 0.164671 0.164671 0.000000 0.000000 0.082288 0.082288 0.065761 0.065761 0.000000 0.164671 0.164671 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.238178 0.238178 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1 0.000000 0.000000 0.083401 0.083401 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.166898 0.166898 0.139874 0.139874 0.000000 0.000000 0.279748 0.279748 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.066651 0.000000 0.166898 0.166898 0.000000 0.000000 0.000000 0.000000 0.166898 0.139874 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.066651 0.066651 0.066651 0.066651 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.083401 0.083401 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.139874 0.000000 0.166898 0.000000 0.000000 0.000000 0.166898 0.166898 0.139874 0.139874 0.000000 0.000000 0.000000 0.000000 0.083401 0.083401 0.066651 0.066651 0.000000 0.000000 0.000000 0.279748 0.279748 0.000000 0.000000 0.279748 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.279748 0.279748 0.139874 0.139874 2 0.000000 0.000000 0.141635 0.141635 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.237540 0.237540 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.237540 0.237540 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.113189 0.000000 0.000000 0.000000 0.237540 0.237540 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.113189 0.113189 0.113189 0.113189 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.141635 0.141635 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.237540 0.237540 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.141635 0.141635 0.113189 0.113189 0.237540 0.000000 0.000000 0.237540 0.237540 0.000000 0.000000 0.237540 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.237540 0.237540 0.000000 0.000000 3 0.000000 0.000000 0.120227 0.120227 0.000000 0.000000 0.000000 0.000000 0.240593 0.240593 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.173995 0.173995 0.000000 0.000000 0.000000 0.000000 0.096080 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.173995 0.000000 0.000000 0.000000 0.096080 0.096080 0.096080 0.096080 0.000000 0.000000 0.000000 0.173995 0.173995 0.240593 0.240593 0.000000 0.000000 0.120227 0.120227 0.000000 0.000000 0.000000 0.000000 0.240593 0.240593 0.000000 0.000000 0.000000 0.000000 0.240593 0.240593 0.240593 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.120227 0.120227 0.096080 0.096080 0.000000 0.000000 0.000000 0.000000 0.000000 0.240593 0.240593 0.000000 0.000000 0.173995 0.173995 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 4 0.000000 0.000000 0.138366 0.138366 0.232057 0.232057 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.232057 0.232057 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.110576 0.276891 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.110576 0.110576 0.110576 0.110576 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.138366 0.138366 0.000000 0.000000 0.232057 0.232057 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.232057 0.000000 0.000000 0.000000 0.232057 0.276891 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.232057 0.232057 0.000000 0.000000 0.000000 0.000000 0.138366 0.138366 0.110576 0.110576 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.232057 0.232057 5 0.000000 0.000000 0.000000 0.000000 0.183573 0.183573 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.183573 0.183573 0.000000 0.000000 0.000000 0.000000 0.219041 0.219041 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.219041 0.219041 0.087474 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.183573 0.183573 0.219041 0.087474 0.087474 0.087474 0.087474 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.219041 0.219041 0.183573 0.183573 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.183573 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.183573 0.183573 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.219041 0.219041 0.000000 0.000000 0.087474 0.087474 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.219041 0.000000 0.000000 0.000000 0.000000 0.219041 0.219041 0.000000 0.000000 0.000000 0.000000 6 0.210123 0.210123 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.210123 0.210123 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.181319 0.181319 0.000000 0.000000 0.000000 0.000000 0.100125 0.000000 0.000000 0.000000 0.000000 0.000000 0.210123 0.210123 0.000000 0.000000 0.250720 0.000000 0.000000 0.181319 0.210123 0.210123 0.000000 0.100125 0.100125 0.100125 0.100125 0.210123 0.250720 0.000000 0.181319 0.181319 0.000000 0.000000 0.210123 0.210123 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.210123 0.210123 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.100125 0.100125 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.181319 0.181319 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 7 0.000000 0.000000 0.141163 0.141163 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.236749 0.236749 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.282490 0.282490 0.000000 0.000000 0.112812 0.000000 0.000000 0.000000 0.236749 0.236749 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.112812 0.112812 0.112812 0.112812 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.141163 0.141163 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.236749 0.236749 0.282490 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.141163 0.141163 0.112812 0.112812 0.236749 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.282490 0.282490 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
1102
예제문제 만들기
corpus = ["코로나 거리두기와 코로나 상생지원금 문의입니다.",
"지하철 운행시간과 지하철 요금 문의입니다.",
"지하철 승강장 문의입니다.",
"코로나 선별진료소 문의입니다.",
"버스 운행시간 문의입니다.",
"버스 터미널 위치 안내입니다.",
"코로나 거리두기 안내입니다.",
"택시 승강장 문의입니다."
]
df = pd.DataFrame(corpus)
df.columns = ["문서"]
df
| 문서 | |
|---|---|
| 0 | 코로나 거리두기와 코로나 상생지원금 문의입니다. |
| 1 | 지하철 운행시간과 지하철 요금 문의입니다. |
| 2 | 지하철 승강장 문의입니다. |
| 3 | 코로나 선별진료소 문의입니다. |
| 4 | 버스 운행시간 문의입니다. |
| 5 | 버스 터미널 위치 안내입니다. |
| 6 | 코로나 거리두기 안내입니다. |
| 7 | 택시 승강장 문의입니다. |
정답 데이터 만들기
# str.contains 를 통해 특정 텍스트가 들어가는 여부를 알 수 있음
# "코로나" 가 들어가는 텍스트 찾기
# "코로나"가 포함이면 "보건"으로 나머지는 "교통" 으로 정답을 레이블링
df.loc[df["문서"].str.contains("코로나"), "분류"] = "보건"
df.loc[~df["문서"].str.contains("코로나"), "분류"] = "교통"
df
| 문서 | 분류 | |
|---|---|---|
| 0 | 코로나 거리두기와 코로나 상생지원금 문의입니다. | 보건 |
| 1 | 지하철 운행시간과 지하철 요금 문의입니다. | 교통 |
| 2 | 지하철 승강장 문의입니다. | 교통 |
| 3 | 코로나 선별진료소 문의입니다. | 보건 |
| 4 | 버스 운행시간 문의입니다. | 교통 |
| 5 | 버스 터미널 위치 안내입니다. | 교통 |
| 6 | 코로나 거리두기 안내입니다. | 보건 |
| 7 | 택시 승강장 문의입니다. | 교통 |
# 정답 값 빈도수 확인하기
df["분류"].value_counts()
out:
교통 5
보건 3
Name: 분류, dtype: int64
텍스트 데이터 수치 형태로 변경하기
# sklearn.feature_extraction.text의 TfidfVectorizer 로 BOW 벡터화
# fit_transform 으로 변환하기
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfvect = TfidfVectorizer()
dtm = tfidfvect.fit_transform(df["문서"])
DTM(Document to Metrix)
# dtm(document-term matrix)
df_dtm = pd.DataFrame(dtm.toarray(), columns = tfidfvect.get_feature_names_out())
df_dtm.style.background_gradient()
-
out
거리두기 거리두기와 문의입니다 버스 상생지원금 선별진료소 승강장 안내입니다 요금 운행시간 운행시간과 위치 지하철 코로나 택시 터미널 0 0.000000 0.479919 0.239821 0.000000 0.479919 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.694148 0.000000 0.000000 1 0.000000 0.000000 0.222166 0.000000 0.000000 0.000000 0.000000 0.000000 0.444589 0.000000 0.444589 0.000000 0.745200 0.000000 0.000000 0.000000 2 0.000000 0.000000 0.388500 0.000000 0.000000 0.000000 0.651563 0.000000 0.000000 0.000000 0.000000 0.000000 0.651563 0.000000 0.000000 0.000000 3 0.000000 0.000000 0.375318 0.000000 0.000000 0.751070 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.543168 0.000000 0.000000 4 0.000000 0.000000 0.357659 0.599839 0.000000 0.000000 0.000000 0.000000 0.000000 0.715732 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 5 0.000000 0.000000 0.000000 0.454195 0.000000 0.000000 0.000000 0.454195 0.000000 0.000000 0.000000 0.541948 0.000000 0.000000 0.000000 0.541948 6 0.670344 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.561801 0.000000 0.000000 0.000000 0.000000 0.000000 0.484788 0.000000 0.000000 7 0.000000 0.000000 0.357659 0.000000 0.000000 0.000000 0.599839 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.715732 0.000000
문제와 정답 만들기
X = df_dtm
y = df["분류"]
데이터 셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, stratify= y, random_state=42)
다른 방법
# 8:2 의 비율로 구하기 위해 전체 데이터의 행에서 80% 위치에 해당되는 값을 구해서 split_count 라는 변수에 담는다.
split_count =int(X.shape[0] * 0.8)
split_count
# 학습 세트 만들기 예) 시험의 기출문제
# 학습 세트의 정답 만들기 예) 기출문제의 정답
# X_train, y_train
# X_train = X.sample(frac=0.8, random_state=0)
X_train = X[:split_count]
y_train = y[X_train.index]
X_train.shape, y_train.shape
y_train.value_counts()
# 예측 세트 만들기 예) 실전 시험문제
# 예측 세트의 정답 만들기 예) 실전 문제의 정답
# X_test, y_test
X_test = X.drop(X_train.index)
y_test = y[X_test.index]
X_test.shape, y_test.shape
y_test.value_counts()
모델 로드 및 학습과 예측, 정확도 측정, 시각화
# 모델 로드
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=42)
#학습 : fit(기출문제, 정답)
model.fit(X_train, y_train)
# 예측 : predict(실전문제)
y_predict = model.predict(X_test)
# 정확도 측정
(y_test == y_predict).mean()
out:
1.0
# crosstab 으로 confusion matrix 구현
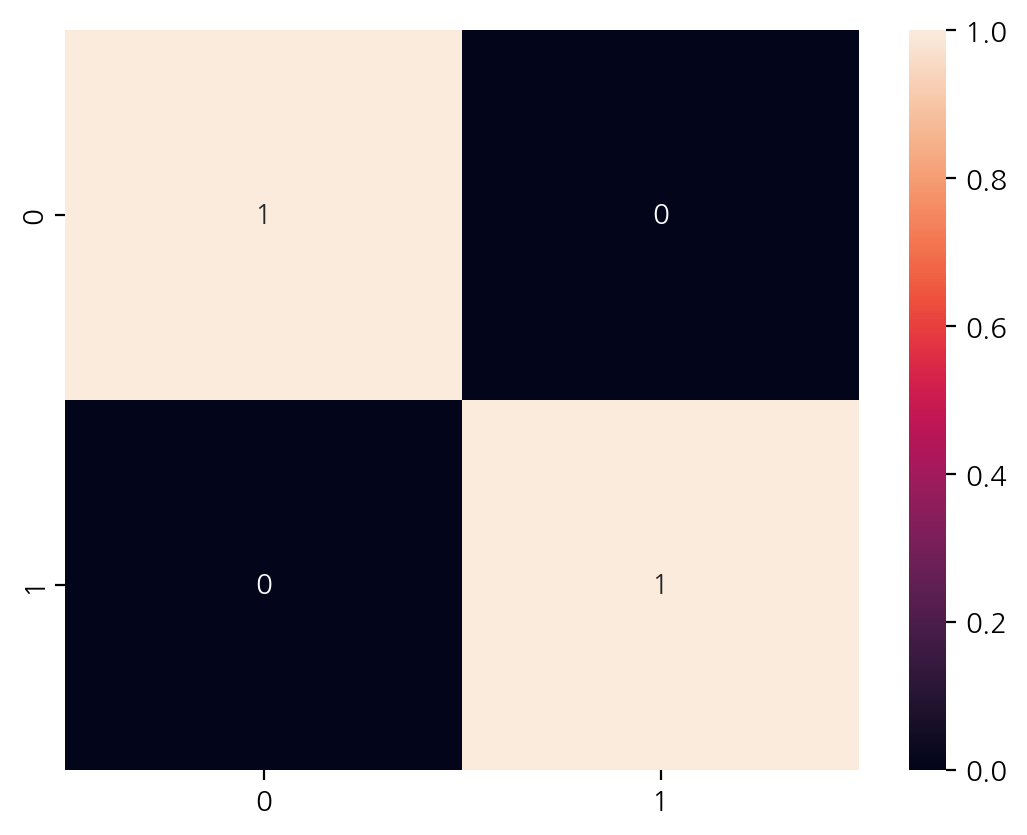
pd.crosstab(y_test, y_predict)
| col_0 | 교통 | 보건 |
|---|---|---|
| 분류 | ||
| 교통 | 1 | 0 |
| 보건 | 0 | 1 |
# confusion matrix 시각화
from sklearn.metrics import confusion_matrix
sns.heatmap(confusion_matrix(y_test, y_predict), annot= True)
트리 알고리즘 분석
# export_text 로 트리 분석하기
from sklearn.tree import export_text
print(export_text(model, feature_names= X.columns.tolist()))
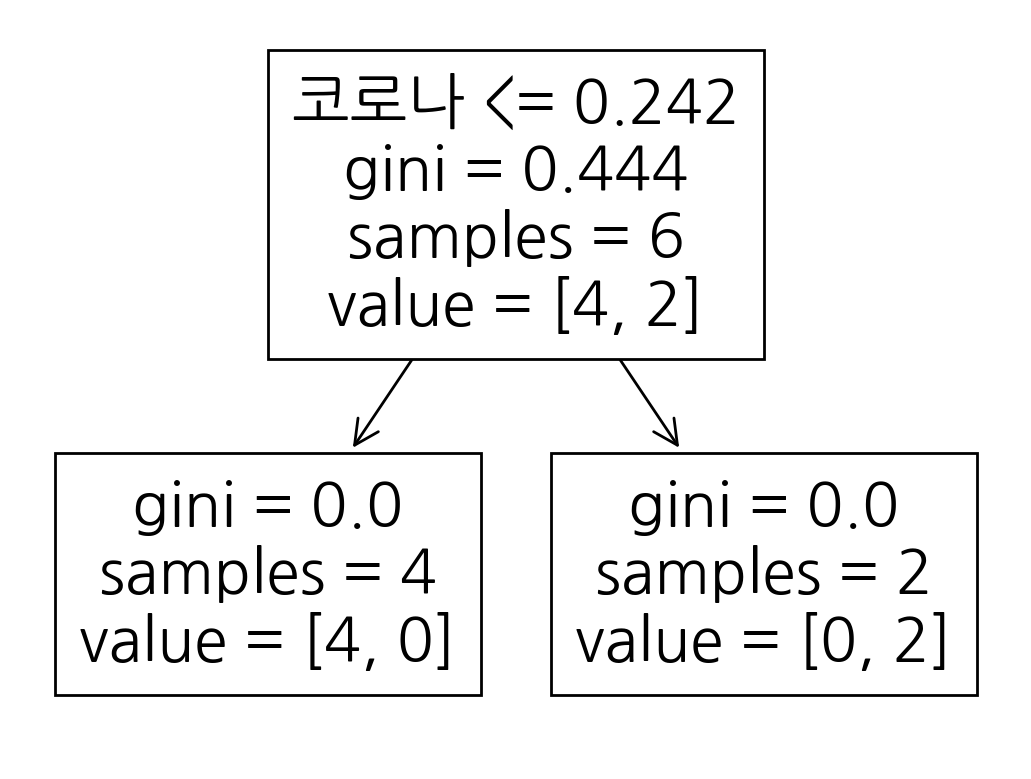
out:
|--- 코로나 <= 0.24
| |--- class: 교통
|--- 코로나 > 0.24
| |--- class: 보건
# plot_tree 로 시각화 하기
from sklearn.tree import plot_tree
tree = plot_tree(model, feature_names= X.columns.tolist())
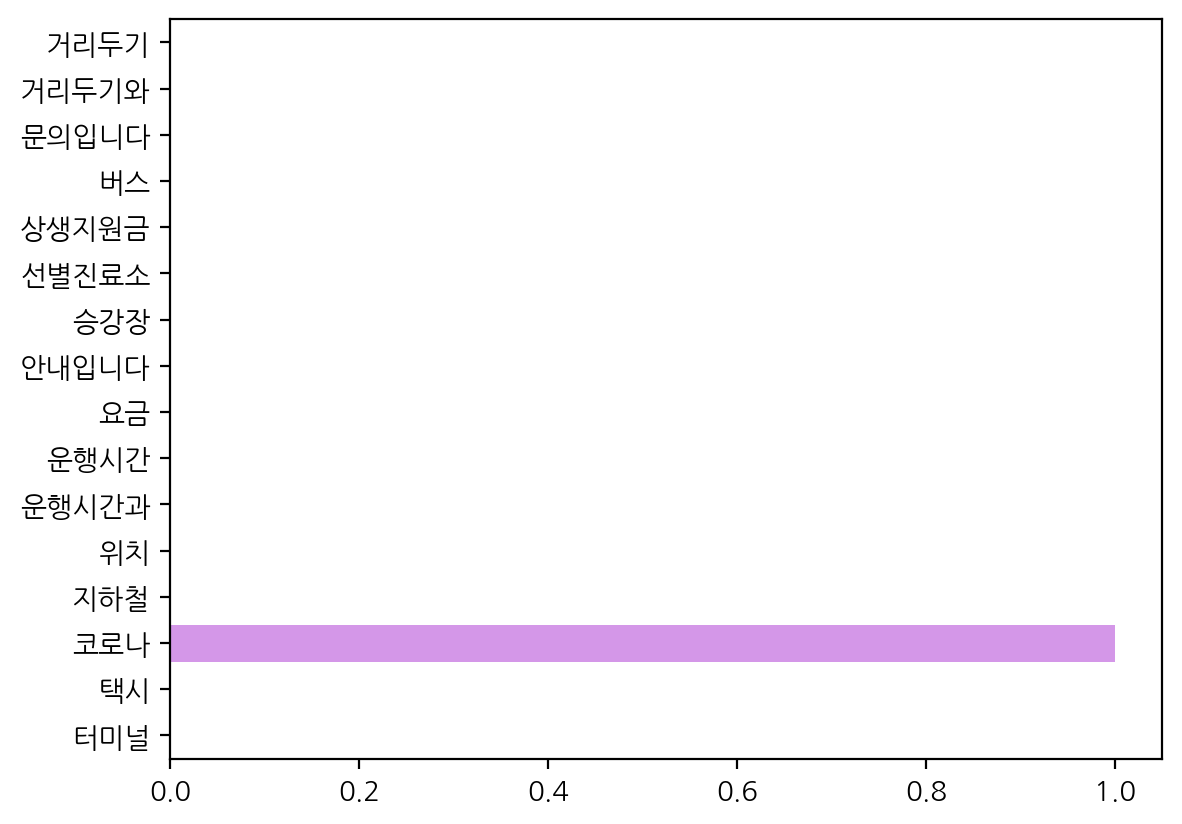
# feature_importances_로 피처 중요도 확인하기
sns.barplot(x = model.feature_importances_, y = model.feature_names_in_)
연합뉴스 타이틀 주제 분류 데이터 탐색과 시각화
# wordcloud 설치 아나콘다 사용시 conda 명령어 설치 권장
# !pip install wordcloud
# !conda install -c conda-forge wordcloud
라이브러리, 데이터 로드
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import koreanize_matplotlib
# 파일 경로(file_bath)는 본인 컴퓨터에 저장된 경로로 지정해준다.
train = pd.read_csv(f"{file_bath}train_data.csv", index_col = "index")
test = pd.read_csv(f"{file_bath}test_data.csv", index_col = "index")
topic = pd.read_csv(f"{file_bath}topic_dict.csv")
전처리를 위한 데이터 병합
# 토픽에 어떤 값이 있는지 values로 확인
train["topic_idx"].values
out:
array([4, 4, 4, ..., 1, 2, 2], dtype=int64)
concat
raw = pd.concat([train, test])
raw.shape
out:
(54785, 2)
raw.head(2)
| title | topic_idx | |
|---|---|---|
| index | ||
| 0 | 인천→핀란드 항공기 결항…휴가철 여행객 분통 | 4.0 |
| 1 | 실리콘밸리 넘어서겠다…구글 15조원 들여 美전역 거점화 | 4.0 |
raw.tail(2)
| title | topic_idx | |
|---|---|---|
| index | ||
| 54783 | 게시판 아리랑TV 아프리카개발은행 총회 개회식 생중계 | NaN |
| 54784 | 유영민 과기장관 강소특구는 지역 혁신의 중심…지원책 강구 | NaN |
merge
df = pd.merge(raw, topic, how = "left")
df.shape
out:
(54785, 3)
df.head()
| title | topic_idx | topic | |
|---|---|---|---|
| 0 | 인천→핀란드 항공기 결항…휴가철 여행객 분통 | 4.0 | 세계 |
| 1 | 실리콘밸리 넘어서겠다…구글 15조원 들여 美전역 거점화 | 4.0 | 세계 |
| 2 | 이란 외무 긴장완화 해결책은 미국이 경제전쟁 멈추는 것 | 4.0 | 세계 |
| 3 | NYT 클린턴 측근韓기업 특수관계 조명…공과 사 맞물려종합 | 4.0 | 세계 |
| 4 | 시진핑 트럼프에 중미 무역협상 조속 타결 희망 | 4.0 | 세계 |
정답값 빈도수
df["topic_idx"].value_counts()
out:
4.0 7629
2.0 7362
5.0 6933
6.0 6751
1.0 6222
3.0 5933
0.0 4824
Name: topic_idx, dtype: int64
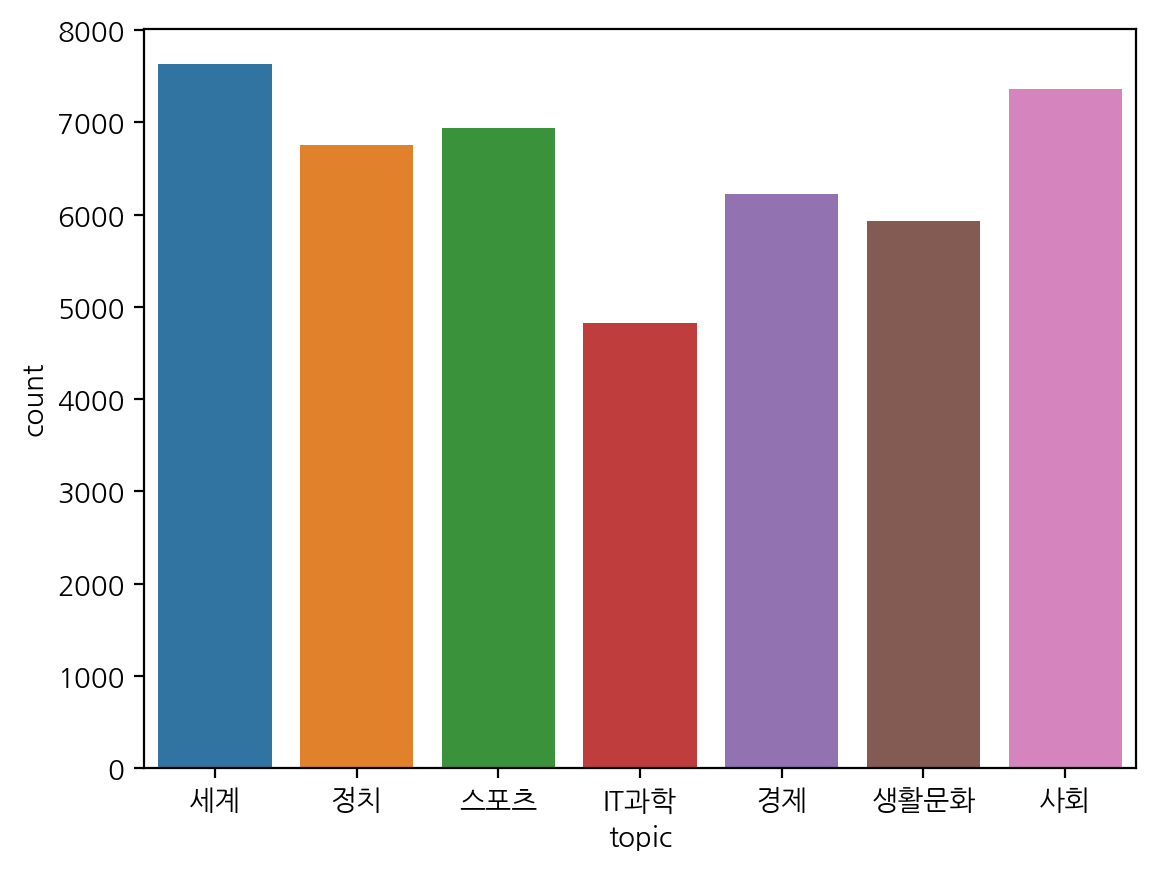
df["topic"].value_counts()
out:
세계 7629
사회 7362
스포츠 6933
정치 6751
경제 6222
생활문화 5933
IT과학 4824
Name: topic, dtype: int64
sns.countplot(data = df, x = "topic")
문자 길이
# apply, lambda를 통해 문자, 단어 빈도수 파생변수 만들기
df["len"] = df["title"].map(lambda x: len(x))
df["word_count"] = df["title"].map(lambda x: len(x.split())) # 더 정밀하게 하기 위해선 형태소 분석기 사용 예정
df["unique_word_count"] = df["title"].map(lambda x: len(set(x.split())))
df.head()
| title | topic_idx | topic | len | word_count | unique_word_count | |
|---|---|---|---|---|---|---|
| 0 | 인천→핀란드 항공기 결항…휴가철 여행객 분통 | 4.0 | 세계 | 24 | 5 | 5 |
| 1 | 실리콘밸리 넘어서겠다…구글 15조원 들여 美전역 거점화 | 4.0 | 세계 | 30 | 6 | 6 |
| 2 | 이란 외무 긴장완화 해결책은 미국이 경제전쟁 멈추는 것 | 4.0 | 세계 | 30 | 8 | 8 |
| 3 | NYT 클린턴 측근韓기업 특수관계 조명…공과 사 맞물려종합 | 4.0 | 세계 | 32 | 7 | 7 |
| 4 | 시진핑 트럼프에 중미 무역협상 조속 타결 희망 | 4.0 | 세계 | 25 | 7 | 7 |
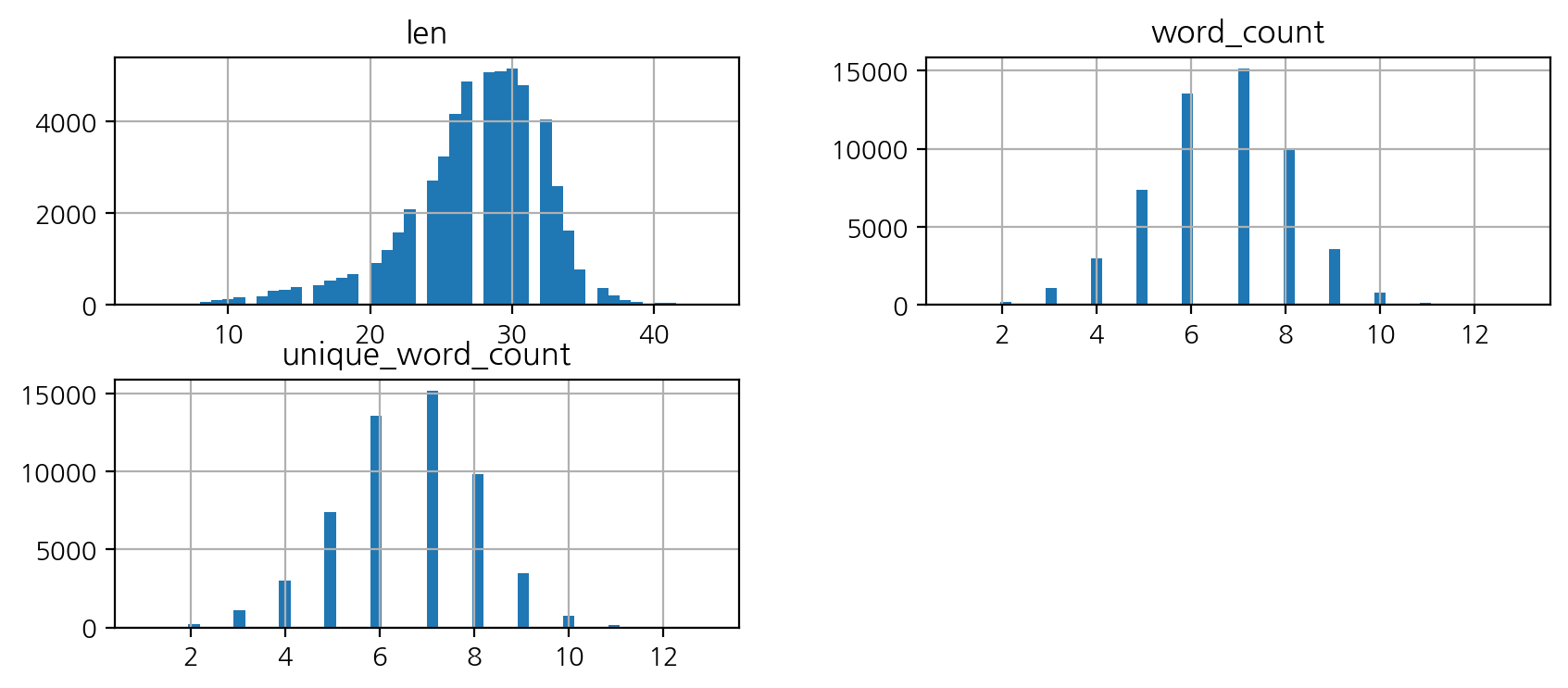
# histplot
df[['len', 'word_count', 'unique_word_count']].hist(figsize = (10,4), bins = 50);
# describe
df[['len', 'word_count', 'unique_word_count']].describe()
| len | word_count | unique_word_count | |
|---|---|---|---|
| count | 54785.000000 | 54785.000000 | 54785.000000 |
| mean | 27.318846 | 6.587880 | 6.576198 |
| std | 4.947738 | 1.471852 | 1.465320 |
| min | 4.000000 | 1.000000 | 1.000000 |
| 25% | 25.000000 | 6.000000 | 6.000000 |
| 50% | 28.000000 | 7.000000 | 7.000000 |
| 75% | 31.000000 | 8.000000 | 8.000000 |
| max | 44.000000 | 13.000000 | 13.000000 |
# 5글자 미만 확인
df[df["len"]<5]
| title | topic_idx | topic | len | word_count | unique_word_count | |
|---|---|---|---|---|---|---|
| 43922 | 국무회의 | 6.0 | 정치 | 4 | 1 | 1 |
| 49997 | 봄 산책 | NaN | NaN | 4 | 2 | 2 |
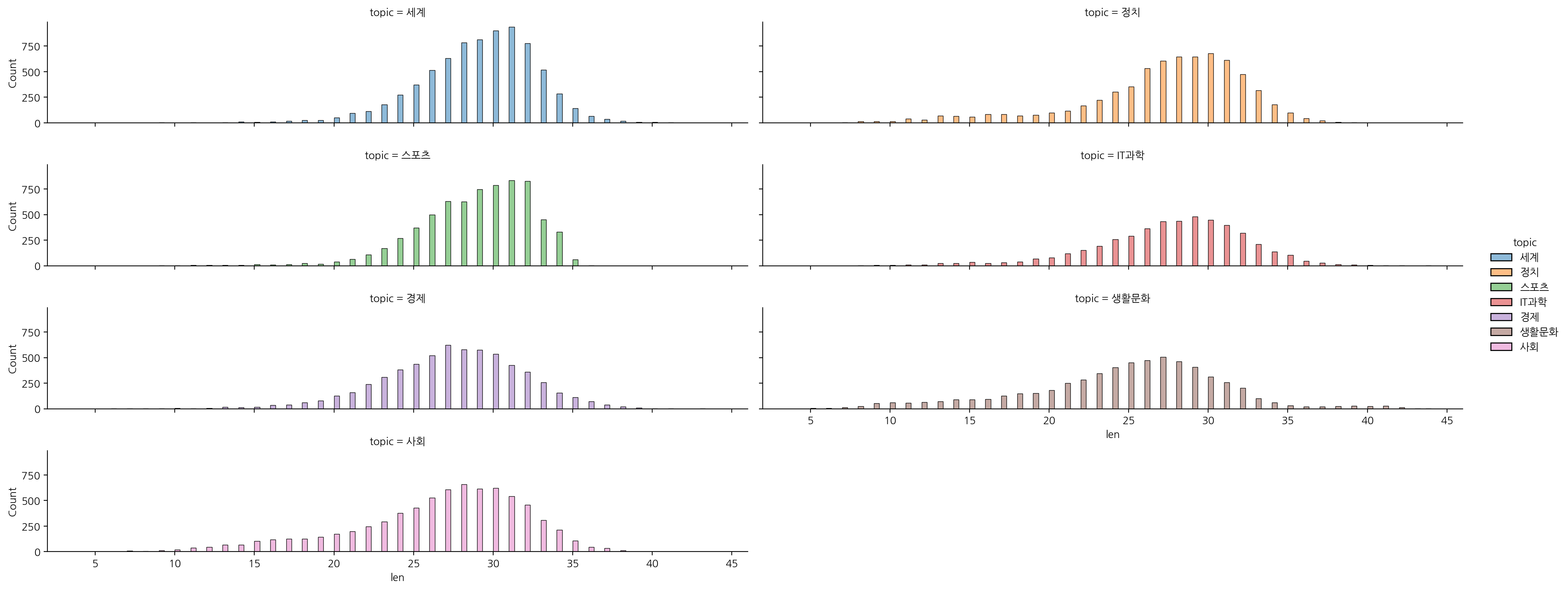
# 토픽 별 단어 길이 확인
sns.displot(data = df, x = "len", hue = "topic", col="topic", col_wrap=2, aspect=5, height=2)
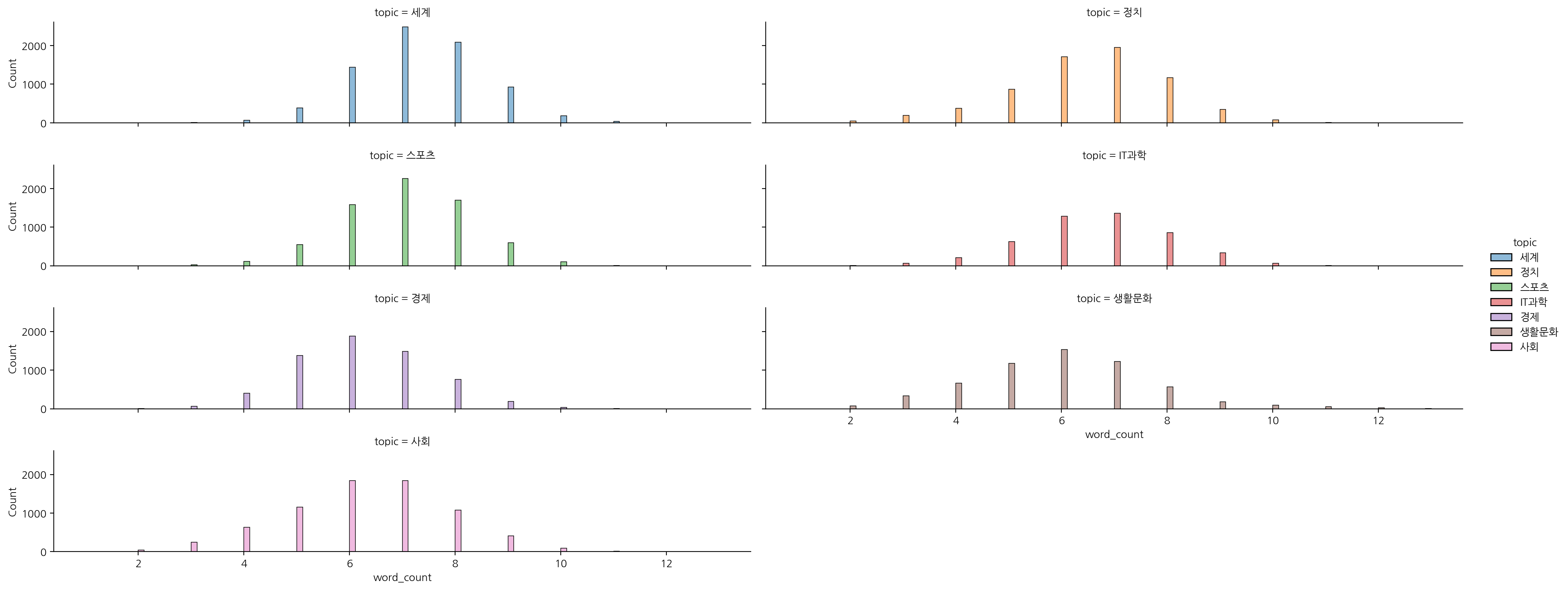
sns.displot(data = df, x = "word_count", hue = "topic", col="topic", col_wrap=2, aspect=5, height=2)
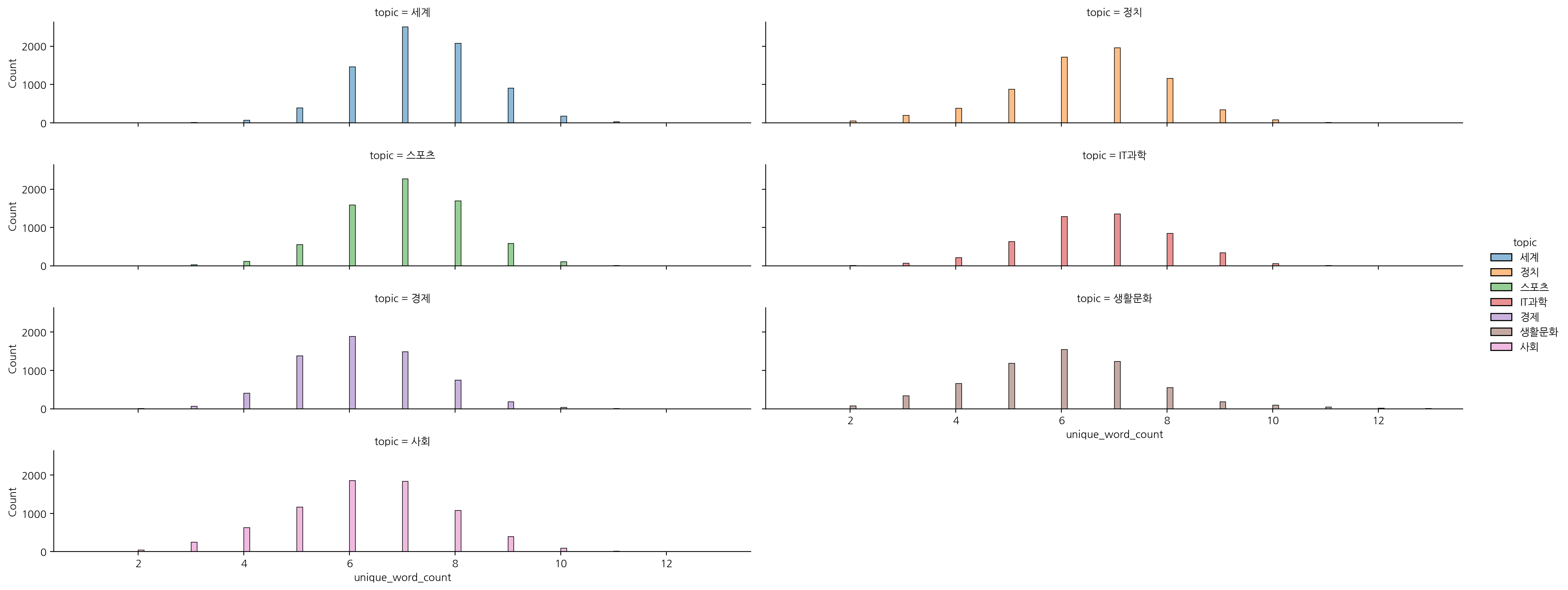
sns.displot(data = df, x = "unique_word_count", hue = "topic", col="topic", col_wrap=2, aspect=5, height=2)
# heatmap 을 통한 "len", "word_count", "unique_word_count" 시각화
sns.heatmap(data = df[["len", "word_count", "unique_word_count"]], cmap = "Blues");
문자 전처리
숫자 제거
정규표현식을 이용해서 다양한 방식으로 특정 문자를 제거해본다.
# map, 정규표현식의 re.sub 을 통해 숫자제거
import re
df["title"].map(lambda x : re.sub("[0-9]", "", x))
out:
0 인천→핀란드 항공기 결항…휴가철 여행객 분통
1 실리콘밸리 넘어서겠다…구글 조원 들여 美전역 거점화
2 이란 외무 긴장완화 해결책은 미국이 경제전쟁 멈추는 것
3 NYT 클린턴 측근韓기업 특수관계 조명…공과 사 맞물려종합
4 시진핑 트럼프에 중미 무역협상 조속 타결 희망
...
54780 인천 오후 시분 대설주의보…눈 .cm 쌓여
54781 노래방에서 지인 성추행 외교부 사무관 불구속 입건종합
54782 년 전 부마항쟁 부산 시위 사진 점 최초 공개
54783 게시판 아리랑TV 아프리카개발은행 총회 개회식 생중계
54784 유영민 과기장관 강소특구는 지역 혁신의 중심…지원책 강구
Name: title, Length: 54785, dtype: object
# 판다스의 str.replace 기능을 통해 제거
df["title"] = df["title"].str.replace("[0-9]", "", regex = True)
df["title"]
out:
0 인천→핀란드 항공기 결항…휴가철 여행객 분통
1 실리콘밸리 넘어서겠다…구글 조원 들여 美전역 거점화
2 이란 외무 긴장완화 해결책은 미국이 경제전쟁 멈추는 것
3 NYT 클린턴 측근韓기업 특수관계 조명…공과 사 맞물려종합
4 시진핑 트럼프에 중미 무역협상 조속 타결 희망
...
54780 인천 오후 시분 대설주의보…눈 .cm 쌓여
54781 노래방에서 지인 성추행 외교부 사무관 불구속 입건종합
54782 년 전 부마항쟁 부산 시위 사진 점 최초 공개
54783 게시판 아리랑TV 아프리카개발은행 총회 개회식 생중계
54784 유영민 과기장관 강소특구는 지역 혁신의 중심…지원책 강구
Name: title, Length: 54785, dtype: object
특수 문자 제거
# 특수 문자 제거 시 구두점 참고
import string
punct = string.punctuation
punct
out:
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
# 특수 문자 사용시 정규표현식에서 메타 문자로 특별한 의미를 갖기 때문에 역슬래시를 통해 예외처리를 해주어야 한다.
# [!\"\$\*] 일부 특수문자 제거 연습
df["title"] = df["title"].str.replace("[!\"\$\*]", "", regex= True)
df["title"]
out:
0 인천→핀란드 항공기 결항…휴가철 여행객 분통
1 실리콘밸리 넘어서겠다…구글 조원 들여 美전역 거점화
2 이란 외무 긴장완화 해결책은 미국이 경제전쟁 멈추는 것
3 NYT 클린턴 측근韓기업 특수관계 조명…공과 사 맞물려종합
4 시진핑 트럼프에 중미 무역협상 조속 타결 희망
...
54780 인천 오후 시분 대설주의보…눈 .cm 쌓여
54781 노래방에서 지인 성추행 외교부 사무관 불구속 입건종합
54782 년 전 부마항쟁 부산 시위 사진 점 최초 공개
54783 게시판 아리랑TV 아프리카개발은행 총회 개회식 생중계
54784 유영민 과기장관 강소특구는 지역 혁신의 중심…지원책 강구
Name: title, Length: 54785, dtype: object
영어, 한글 전처리
# 대문자 -> 소문자로 변경
df["title"] = df["title"].str.lower()
# 한글과 영어와 공백만 남기고 제거
df["title"] = df["title"].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 a-zA-Z]", "", regex = True)
df["title"]
out:
0 인천핀란드 항공기 결항휴가철 여행객 분통
1 실리콘밸리 넘어서겠다구글 조원 들여 전역 거점화
2 이란 외무 긴장완화 해결책은 미국이 경제전쟁 멈추는 것
3 nyt 클린턴 측근기업 특수관계 조명공과 사 맞물려종합
4 시진핑 트럼프에 중미 무역협상 조속 타결 희망
...
54780 인천 오후 시분 대설주의보눈 cm 쌓여
54781 노래방에서 지인 성추행 외교부 사무관 불구속 입건종합
54782 년 전 부마항쟁 부산 시위 사진 점 최초 공개
54783 게시판 아리랑tv 아프리카개발은행 총회 개회식 생중계
54784 유영민 과기장관 강소특구는 지역 혁신의 중심지원책 강구
Name: title, Length: 54785, dtype: object
여러개의 공백 전처리
# 공백 여러 개 전처리 예시
import re
re.sub("[\s]+", " ", "공백 전처리")
out:
'공백 전처리'
re.sub("[ㅎ]+", "ㅎ", "ㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎ")
out:
'ㅎ'
re.sub("[ㅋ]+", "ㅋ", "ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ")
out:
'ㅋ'
df["title"] = df["title"].str.replace("[\s]+","", regex= True)
df["title"]
out:
0 인천핀란드항공기결항휴가철여행객분통
1 실리콘밸리넘어서겠다구글조원들여전역거점화
2 이란외무긴장완화해결책은미국이경제전쟁멈추는것
3 nyt클린턴측근기업특수관계조명공과사맞물려종합
4 시진핑트럼프에중미무역협상조속타결희망
...
54780 인천오후시분대설주의보눈cm쌓여
54781 노래방에서지인성추행외교부사무관불구속입건종합
54782 년전부마항쟁부산시위사진점최초공개
54783 게시판아리랑tv아프리카개발은행총회개회식생중계
54784 유영민과기장관강소특구는지역혁신의중심지원책강구
Name: title, Length: 54785, dtype: object
불용어 제거
# 불용어 제거
def remove_stopwords(text):
tokens = text.split(' ')
stops = [ '합니다', '하는', '할', '하고', '한다',
'그리고', '입니다', '그', '등', '이런', '및','제', '더']
meaningful_words = [w for w in tokens if not w in stops]
return ' '.join(meaningful_words)
# map을 사용하여 불용어 제거하기
df["title"] = df["title"].map(lambda x : remove_stopwords(x))
df["title"]
out:
0 인천핀란드항공기결항휴가철여행객분통
1 실리콘밸리넘어서겠다구글조원들여전역거점화
2 이란외무긴장완화해결책은미국이경제전쟁멈추는것
3 nyt클린턴측근기업특수관계조명공과사맞물려종합
4 시진핑트럼프에중미무역협상조속타결희망
...
54780 인천오후시분대설주의보눈cm쌓여
54781 노래방에서지인성추행외교부사무관불구속입건종합
54782 년전부마항쟁부산시위사진점최초공개
54783 게시판아리랑tv아프리카개발은행총회개회식생중계
54784 유영민과기장관강소특구는지역혁신의중심지원책강구
Name: title, Length: 54785, dtype: object
워드 클라우드
공식문서의 튜토리얼을 보고 wordcloud를 그리는 함수를 만들어 보도록 한다. 이때 폰트 설정시 폰트명이 아닌 폰트의 설치 경로를 입력해 주어야 한다.
윈도우 : r"C:\Windows\Fonts\malgun.ttf" 해당 경로에 폰트가 있는지 확인
맥 : r"/Library/Fonts/AppleGothic.ttf"
나눔고딕 등의 폰트를 설치했다면 : '/Library/Fonts/NanumBarunGothic.ttf'
from wordcloud import WordCloud
def display_word_cloud(data, width=1200, height=500):
word_draw = WordCloud(
font_path=r"C:\Windows\Fonts\malgun.ttf", # 윈도우 환경
width=width, height=height,
stopwords=["합니다", "입니다"],
background_color="white",
random_state=42
)
word_draw.generate(data)
plt.figure(figsize=(15, 7))
plt.imshow(word_draw)
plt.axis("off")
plt.show()
# join()을 이용하여 변수 title 리스트에서 문자열로 변환해 줍니다.
# content
display_word_cloud(" ".join(df["title"]))

