
선형회귀 모델, Gradient Boosting의 종류
⚠️ 해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료를 토대로 정리한 내용입니다.
11/16 : Gradient Boosting의 종류
지난 포스팅에서 이어짐
One-Hot-Encoding
# 모델에 사용할 수 없는 숫자 이외의 데이터가 있는지 확인한다.
# 변환할 피처가 남아있는지 확인한다.
df_test.select_dtypes(exclude="number")[:2]

학습용 데이터와 검증용 데이터 나누기
X = df_train.drop(columns="y")
y = df_train["y"]
print(X.shape, y.shape)
display(X.head())
display(y.head())
학습, 검증세트 나누기
여기에서는 Hold-Out-validation을 사용할 예정이다. train_test_split 기능으로 train, valid를 나눌 예정이다. valid를 만드는 이유는 제출해 보기 전에 어느 정도의 스코어가 나올지 확인해보기 위함이다. cross validation을 사용하지 않고 Hold-out-validation을 사용할 예정이다. Hold-out-validation은 속도가 cross validation에 비해 빠르다는게 장점이다.
train 데이터를 제출해보기 전에 검증해보기 위해 train 데이터셋으로만 나눴기 때문에 X_train, X_valid로 나누어준다.
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(
X, y, test_size = 0.2, random_state=42)
#test도 나중에 혼란이 없도록 이름을 맞춰준다
X_test = df_test
X_train.shape, X_valid.shape, y_train.shape, y_valid.shape
결과값 : ((3367, 551), (842, 551), (3367,), (842,))
선형회귀모델
선형회귀란?
- 통계학에서, 선형 회귀(線型回歸, 영어: linear regression)는 종속 변수 y와 한 개 이상의 독립 변수 (또는 설명 변수) X와의 선형 상관 관계를 모델링하는 회귀분석 기법이다.
from sklearn.linear_model import LinearRegression
model = LinearRegression(n_jobs= -1)
model
학습
model.fit(X_train, y_train)
R2스코어로 예측을 해본다.
model.score(X_valid, y_valid)
결과값 : -2.1203995300441175e+20
R2스코어는 1에 가까울수록 예측을 잘한 값이다. 해당 결과값은 예측이 매우 잘 안된 것으로 보인다. 이는 선형회귀 모델은 예측력이 떨어지기 때문이다.
예측 및 제출
# 학습한 내용으로 예측을 진행한다
y_predict = model.predict(X_test)
# 예측값을 submisson에 넣어서 제출을 진행한다.
submission["y"] = y_predict
submission.to_csv("data/submit_lr.csv")
결과 확인

굉장히 안좋은 점수가 나온 것을 확인 할 수 있다. 이는 예측이 상당히 잘못된 것으로 판단할 수 있다.
💡선형회귀보다 트리계열 모델을 사용하면 같은 데이터셋임에도 훨씬 나은 성능을 보여준다. 이상치도 포함되어있다. 회귀모델은 이상치에 민감하고 다른 수치데이터에 비해 전처리가 많이 필요하다. 선형회귀는 간단하고 이해하기 쉽다는 장점이 있지만, 설명력이 떨어지는 단점이 있다. 따라서, 선형회귀에 맞는 데이터 셋을 사용한다면 좋은 성능을 낼 수 있다.
지난 포스트에서는 원한 인코딩을 범주형 변수에 해주고, 수치 데이터와 합치는 과정을 배웠다. 이번에는 Ordinal 인코딩 방법도 알아본다. concat => 인덱스 값이 맞지 않으면 제대로 병합되지 않을 수 있기 때문에 인덱스 값에 유의가 필요하다.
다양한 러닝머신 모델에 대한 실습
이번에는 다양한 머신러닝 모델을 사용해보록 한다.
이상치 제거
정답값 y의 이상치를 확인해보자.
train[train["y"]>200]

하나의 이상치가 확인된다. 해당 값을 제외해주자.
# 이상치를 제거하고 사용한다.
train = train[train["y"]<200].copy()
train.shape
결과값 : (4208, 377)
Feature engineering
One-Hot-Encoding
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(handle_unknown="ignore")
train_ohe = ohe.fit_transform(train.drop(columns="y"))
test_ohe = ohe.transform(test)
train_ohe.shape, test_ohe.shape
결과값 : ((4208, 919), (4209, 919))
학습, 검증 데이터셋 나누기
# train 으로 X, y 만들기
X = train_ohe
y = train["y"]
X.shape, y.shape
결과값 : ((4208, 919), (4208,))
# train_test_split을 이용해 X, y 값을 X_train, X_valid, y_train, y_valid 으로 나눈다.
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(
X, y, test_size = 0.33, random_state=42)
X_train.shape, X_valid.shape, y_train.shape, y_valid.shape
결과값 : ((2819, 919), (1389, 919), (2819,), (1389,))
# X_test
X_test = test_ohe
X_test.shape
결과값 : (4209, 919)
모델 실습을 위한 모델의 배경 이론 이해
Bagging과 Boosting의 차이?
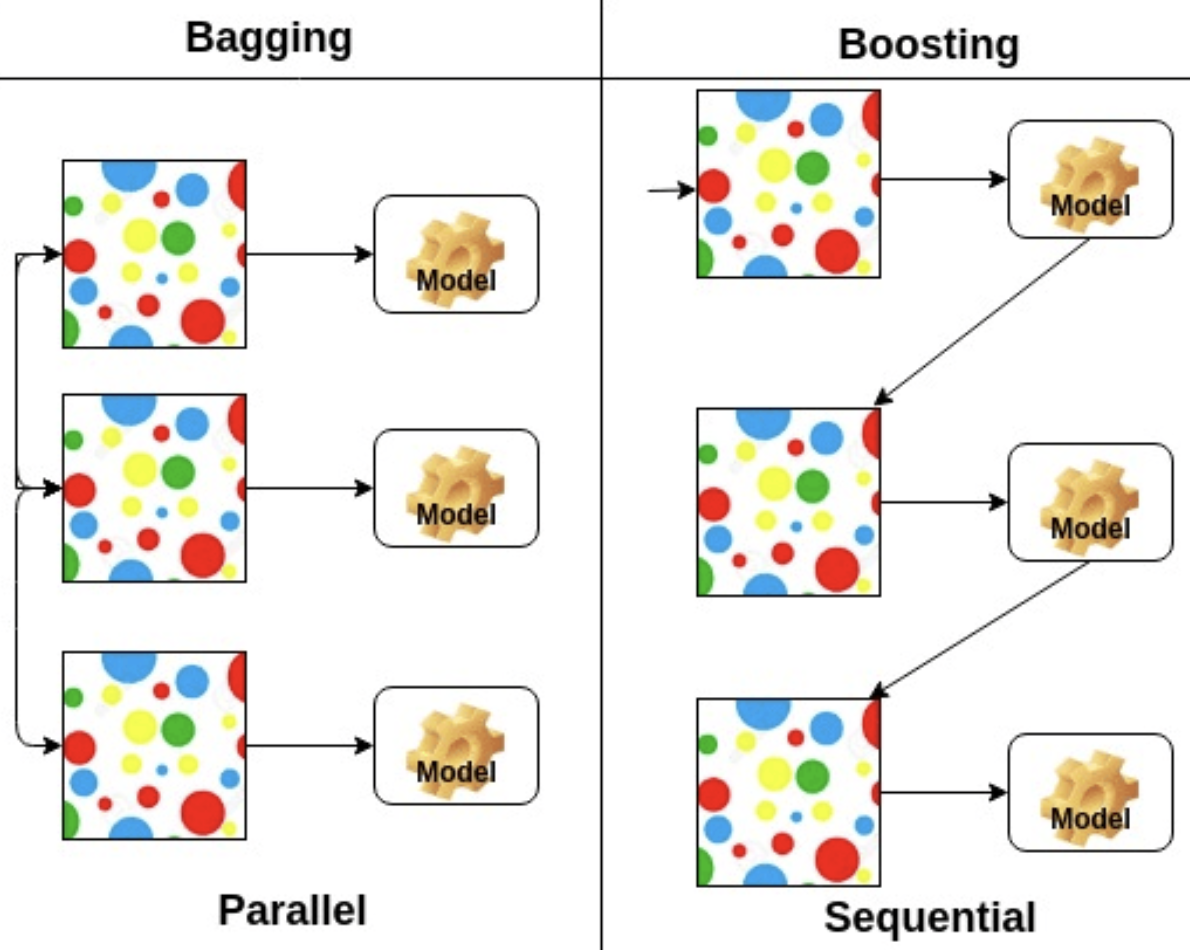
- Bagging : Bagging은 훈련세트에서 중복을 허용해서 샘플링하여 여러개 모델을 훈련 하는 앙상블 방식이다. 같은 훈련 샘플을 여러 개의 모델에 걸쳐 사용해서 모든 모델이 훈련을 마치면 앙상블은 모든 예측기의 예측을 모아서 새로운 샘플에 대한 예측을 만들게 된다.
- Boosting : 부스팅은 약한 모델을 여러개 연결해서 강한 모델을 만들어 내기 위한 앙상블 방식이다. 부스팅의 아이디어는 앞의 모델들을 보완해 나가면서 일련의 모델들을 학습시켜 나가는 것이다. 부스팅에서 대표적인 모델 중 하나는 에이다이다. 에이다 부스트는 앙상블에 이전까지의 오차를 보정하도록 모델을 순차적으로 추가한다. 반면, 그래디언트 부스팅(바로 다음에 나오는 주제이다)은 에이다 부스트와 달리 샘플의 가중치를 수정하는 대신 이전 모델이 만든 잔여 오차에 대해 새로운 모델을 학습시키게 된다.
GBM, XGBoost, LightGBM, Catboost 등 모델이름에 들어가는 ‘G’ 는 무엇을 의미할까?
Gradient(경사, 기울기)를 의미한다. 손실함수 그래프(오차의 제곱을 했을 때 그래프)에서 그래프의 기울기에 따라 양의 방향인지, 음의방향인지를 확인하고 기울기의 값이 가장 낮은 지점(0)으로 경사를 타고 하강한다. 머신러닝에서 예측값과 정답값간의 차이가 손실함수인데 이 크기를 최소화시키는 파라미터를 찾기 위해 사용한다.
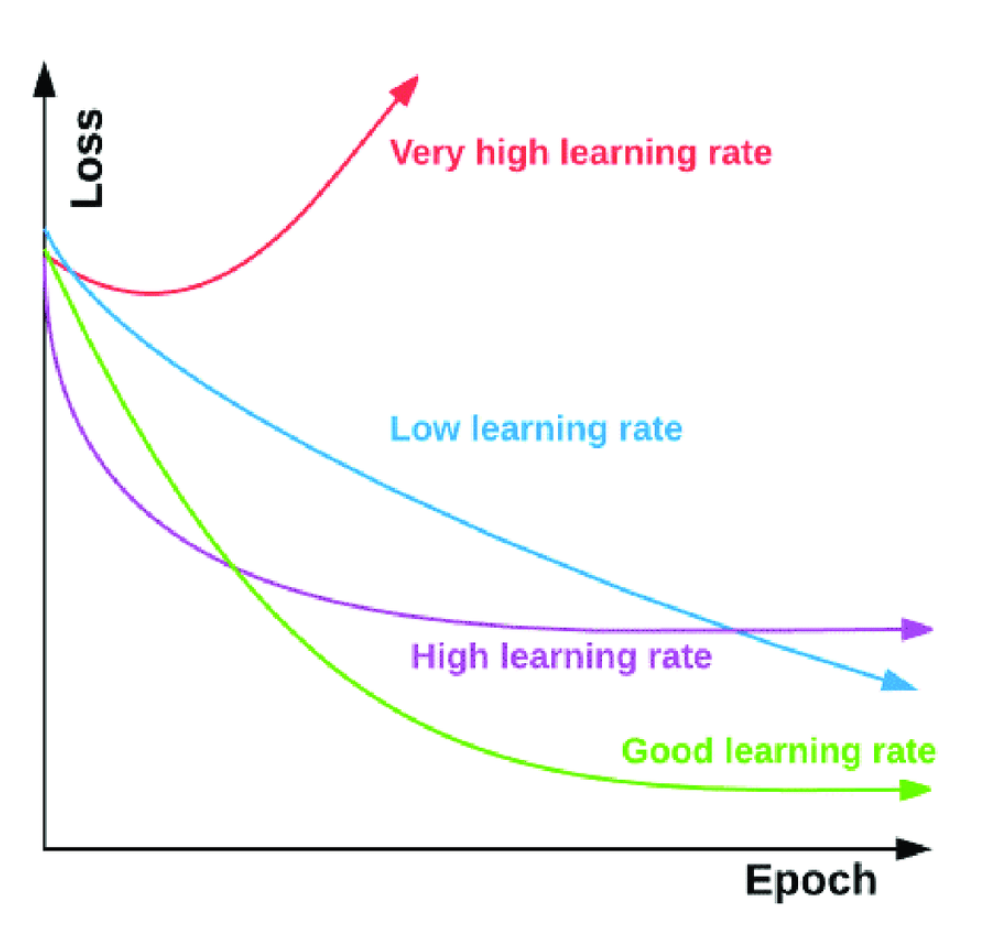
- Learning step(learning rate) : Gradient 단계에서 오차의 최저점을 찾아갈때 얼마 단위로 찾아갈지를 설정한다. 적절한 step을 찾아야 하며, 너무 높은 step은 최저점을 지나쳐 발산을 하게 되며, 너무 낮은 step은 학습속도를 늦추게 만든다. 또한, 적절한 step보다 높은 step 또한 발산을 유발할 수 있다.
- Epoch : n_estimators와 같은 개념이다. 부스팅 트리에서 n_estimators는 몇 번째 트리인지를 의미한다.
GBM(Gradient Boosting Machine)
- 회귀 또는 분류 분석을 수행할 수 있는 예측모형이며, 예측모형의 앙상블 방법론 중 부스팅 계열에 속하는 알고리즘
- 머신러닝 알고리즘 중에서도 가장 예측 성능이 높다고 알려진 알고리즘으로 GBM구현한 패키지들이 다수
- GBM은 계산량이 상당히 많이 필요한 알고리즘이기 때문에, 이를 하드웨어 효율적으로 구현하는 것이 필요
특징
- 랜덤 포레스트와 다르게 무작위성이 없다.
- 매개변수를 잘 조정해야 하고 훈련 시간이 길다.
- 데이터의 스케일에 구애받지 않는다.
- 고차원의 희소한 데이터에 잘 작동하지 않는다.
🤔 GBM 은 왜 랜덤 포레스트와 다르게 무작위성이 없을까?

이전 오차를 보완해서 만들기 때문에 무작위성이 없다. 이전 단계에 틀린 결과만 받아서 가중치를 부여받고 예측을 진행하는 형태이기 때문이다.
GBM(Gradient Boosting Machine) 트리 모델 학습 및 예측
# 모델 호출
from sklearn.ensemble import GradientBoostingRegressor
model_gbt = GradientBoostingRegressor(random_state=42)
# 학습
model_gbt.fit(X_train, y_train)
# valid score
gbt_score= model_gbt.score(X_valid, y_valid)
gbt_score
결과값: 0.5430438083177107
# 예측
y_prid = model_gbt.predict(X_test)
# 제출
submission["y"] = y_prid
file_name = "본인이 저장하고 싶은 위치/submission.csv"

엑스트라 트리 모델(Extremely Randomized Tree) 학습 및 예측
# sklearn.ensemble의 ExtraTreesRegressor는 앙상블 모델 중 엑스트라 트리 모델을 구현한 라이브러리
from sklearn.ensemble import ExtraTreesRegressor
model_et = ExtraTreesRegressor(random_state=42)
# 모델을 학습
model_et.fit(X_train, y_train)
# valid score
et_score = model_et.score(X_valid, y_valid)
et_score
결과값 : 0.27084420987554814
# 예측
y_et_pred = model_et.predict(X_test)
#제출은 GBM과 동일하게 진행한다.

Boosting model input
🤔 부스팅 계열 모델은 설치가 실패하는 경우가 발생하는데 왜일까?
- 기본적으로 다른 언어 환경에서 만들어진 모델이다. 그러하다보니, python에서는 pyhton API를 통해서 구동되는 모델이다.
- 기존에 해당 언어 환경 도구를 설치했다면 비교적 잘 설치가 되지만 그렇치 않은 경우 설치에 실패하는 경우가 많다.
- conda는 비교적 패키징이 잘 되어 있어서 관련된 환경을 잘 구성해 준다. 그래서 가급적이면 conda 환경에서 설치하는 것이 좋다.
- Bagging 방식은 부트스트래핑을 해서 트리를 병렬적으로 여러 개 만들기 때문에 오버피팅 문제에 좀 더 적합하다.
- 개별 트리의 낮은 성능이 문제일 때는 이전 트리의 오차를 보완해 가면서 만들기 때문에 부스팅이 좀 더 적합하다.
XGBoost
- XGBoost는 C++ , Java , Python , R , Julia , Perl 및 Scala 용 정규화 그래디언트 부스팅 프레임워크를 제공 하는 오픈 소스 소프트웨어 라이브러리
- xgboost는 GBT에서 병렬 학습을 지원하여 학습 속도가 빨라진 모델
- 기본 GBT에 비해 더 효율적이고, 다양한 종류의 데이터에 대응할 수 있으며 이식성이 높다.
- 머신 러닝 대회에서 우승한 많은 팀이 선택한 알고리즘으로 최근 많은 인기와 주목을 받고 있다.
| 장점 | 단점 |
|---|---|
| GBM 대비 빠른 수행시간(병렬 처리) | XGBoost는 GBM에 비해 좋은 성능을 보여주고 비교적 빠르지만 그래도 여전히 학습시간이 느림 |
| 과적합 규제(Regularization) | |
| ◦ 표준 GBM 경우 과적합 규제기능이 없으나, XGBoost는 자체에 과적합 규제 기능으로 강한 내구성을 지님 | Hyper Parameter 수가 많아 Hyper Parameter 튜닝을 하게되면 시간이 더욱 오래 걸림 |
| 분류와 회귀영역에서 뛰어난 예측 성능 발휘(광범위한 영역) | 모델의 Overfitting |
| Early Stopping(조기 종료) 기능이 있음 | |
| 다양한 옵션(Hyper Parameter) 을 제공하며 Customizing이 용이 |
LightGBM
- Light Gradient Boosting Machine의 약자인 LightGBM 은 원래 Microsoft에서 개발한 머신 러닝을 위한 오픈 소스 분산 그래디언트 부스팅 프레임워크
- 결정 트리 알고리즘을 기반으로 하며 순위 지정 , 분류 및 기타 기계 학습 작업에 사용
- 개발 초점은 성능과 확장성에 있다.
| 장점 | 단점 |
|---|---|
| 더 빠른 훈련 속도와 더 높은 효율성 | LightGBM은 overfitting (과적합)에 민감하고 작은 데이터에 대해서 과적합되기 쉬움 |
| 적은 메모리 사용량 | |
| 더 나은 정확도 | |
| 병렬, 분산 및 GPU 학습 지원 | |
| 대규모 데이터를 처리 |
CatBoost
- CatBoost는 Yandex에서 개발한 오픈 소스 소프트웨어 라이브러리
- 기존 알고리즘과 비교하여 순열 기반 대안을 사용하여 범주형 기능을 해결하려고 시도 하는 그래디언트 부스팅 프레임워크를 제공
- 다음과 같은 장점이 있다.
- 범주형 기능에 대한 기본 처리
- 빠른 GPU 훈련
- 모델 및 기능 분석을 위한 시각화 및 도구
- 더 빠른 실행을 위해 무시 트리 또는 대칭 트리 사용
- 과적합을 극복하기 위해 순서가 있는 부스팅을 사용
