
Feature engineering의 개념 추가 및 실습
지난 포스팅에서 이어짐
Scaling, 지수함수, 로그함수, Transformation
🤔 왜 데이터를 정규분포 형태로 만들어주면 머신러닝이나 딥러닝에서 더 나은 성능을 내나?
- 너무 한쪽에 몰려있거나 치우쳐져 있을 때보다 고르게 분포되어 있다면 데이터의 특성을 더 고르게 학습할 수 있다.
🤔 음수인 값이 너무 뾰족하거나 치우쳐져 있어서 로그를 취하기 위해서는 어떻게 전처리 해야 할까?
- 1을 더해줘서 로그처리를 해준다.
🤔 너무 큰 음수값이 있을때! 음수인 값이 너무 뾰족하거나 치우쳐져 있어서 로그를 취하기 위해서는 어떻게 전처리 해야 할까? 예를 들어 -1000 이라면?
- 최솟값이 1이 되게 더해주면 됩니다
- 위 예에서는 1001을 더해주면 된다.
- log 처리 후 원래 값으로 돌려주기 위해서는
np.exp(x) -1001을 해주면 된다. inverse_transform으로 복원을 할 수도 있다.
이산화
About cut, qcut
- 이 방법은 RFM 기법에서도 종종 사용되는 방법으로 비즈니스 분석에서 다룰 예정입.
- Recency, Frequency, Monetary => 고객이 얼마나 최근에, 자주, 많이 구매했는지를 분석할 때 사용.
- 이 방법은 RFM 기법에서도 종종 사용되는 방법으로 비즈니스 분석에서 다룰 예정.
- 연속된 수치 데이터를 구간화=> 머신러닝 알고리즘에 힌트를 줄 수도 있다.
- 트리모델이라면 너무 잘게 데이터를 나누지 않아 일반화 하는데 도움이 될 수도 있다.
- 그렇다면 데이터는 나누는 기준이 중요한데, EDA를 통해 어떻게 나누는 것이 예측에 도움이 될지 확인한다.
- 연속된 수치데이터를 나누는 기준에 따라 모델의 성능에 영향을 주게 된다.
- 오히려 잘못나누면 모델의 성능이 떨어질 수도 있다.
인코딩
🤔 LabelEncoder, OrdinalEncoder 의 입력값의 차이?
- Ordinal Encoding은 Label Encoding과 달리 변수에 순서를 고려한다는 점에서 큰 차이를 갖는다. Label Encoding이 알파벳 순서 혹은 데이터셋에 등장하는 순서대로 매핑하는 것과 달리 Oridnal Encoding은 Label 변수의 순서 정보를 사용자가 지정해서 담을 수 있다. LabelEncoder 입력이 1차원 y(label, target, 정답, 시험의 답안, 1차원 벡터) 값, OrdinalEncoder 입력이 2차원 X(독립변수, 시험의 문제, 2차원 array 형태, 학습할 피처)값.
feature_names : 학습(훈련), 예측에 사용할 컬럼을 리스트 형태로 만들어서 변수에 담아줍니다.
label_name : 정답값
X_train : feature_names 에 해당되는 컬럼만 train에서 가져옵니다.
학습(훈련)에 사용할 데이터셋 예) 시험의 기출문제
X_test : feature_names 에 해당되는 컬럼만 test에서 가져옵니다.
예측에 사용할 데이터셋 예) 실전 시험문제
y_train : label_name 에 해당 되는 컬럼만 train에서 가져옵니다.
학습(훈련)에 사용할 정답 값 예) 기출문제의 정답
특성 선택
분산 기반 필터링
# 범주형 변수 중에 어느 하나의 값에 치중되어 분포되어있지 않은지 확인한다.
for col in train.select_dtypes(include="O").columns:
co_count = train[col].value_counts(1)*100
# 어느 변수가 편향된 데이터를 가지는지를 확인하도록 한다.
if co_count[0] > 90:
print(col)
print("-"*15)
결과값 :
Street
---------------
Utilities
---------------
LandSlope
---------------
Condition2
---------------
RoofMatl
---------------
BsmtCond
---------------
Heating
---------------
CentralAir
---------------
Electrical
---------------
Functional
---------------
GarageQual
---------------
GarageCond
---------------
PavedDrive
---------------
MiscFeature
예시로 RoofMatl 의 값을 확인해보도록 한다.
# RoofMatl - value_counts
train["RoofMatl"].value_counts()
결과값 :
CompShg 1434
Tar&Grv 11
WdShngl 6
WdShake 5
Metal 1
Membran 1
Roll 1
ClyTile 1
Name: RoofMatl, dtype: int64
sns.countplot(data=train, x = "RoofMatl")
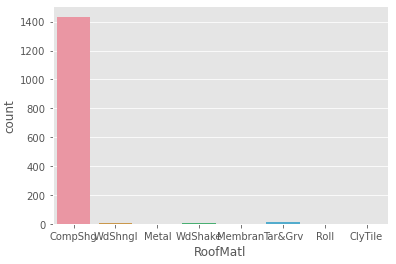
확인한 결과 매우 편향된 데이터를 가지고 있는 것을 확인할 수 있다.
상관관계 기반 필터링
heatmap 기능을 이용해서 상관관계를 표현해보도록 한다.
corr = train.corr()
plt.figure(figsize = (10, 10))
mask = np.triu(np.ones_like(corr))
sns.heatmap(data = corr, mask = mask, cmap = "Blues")
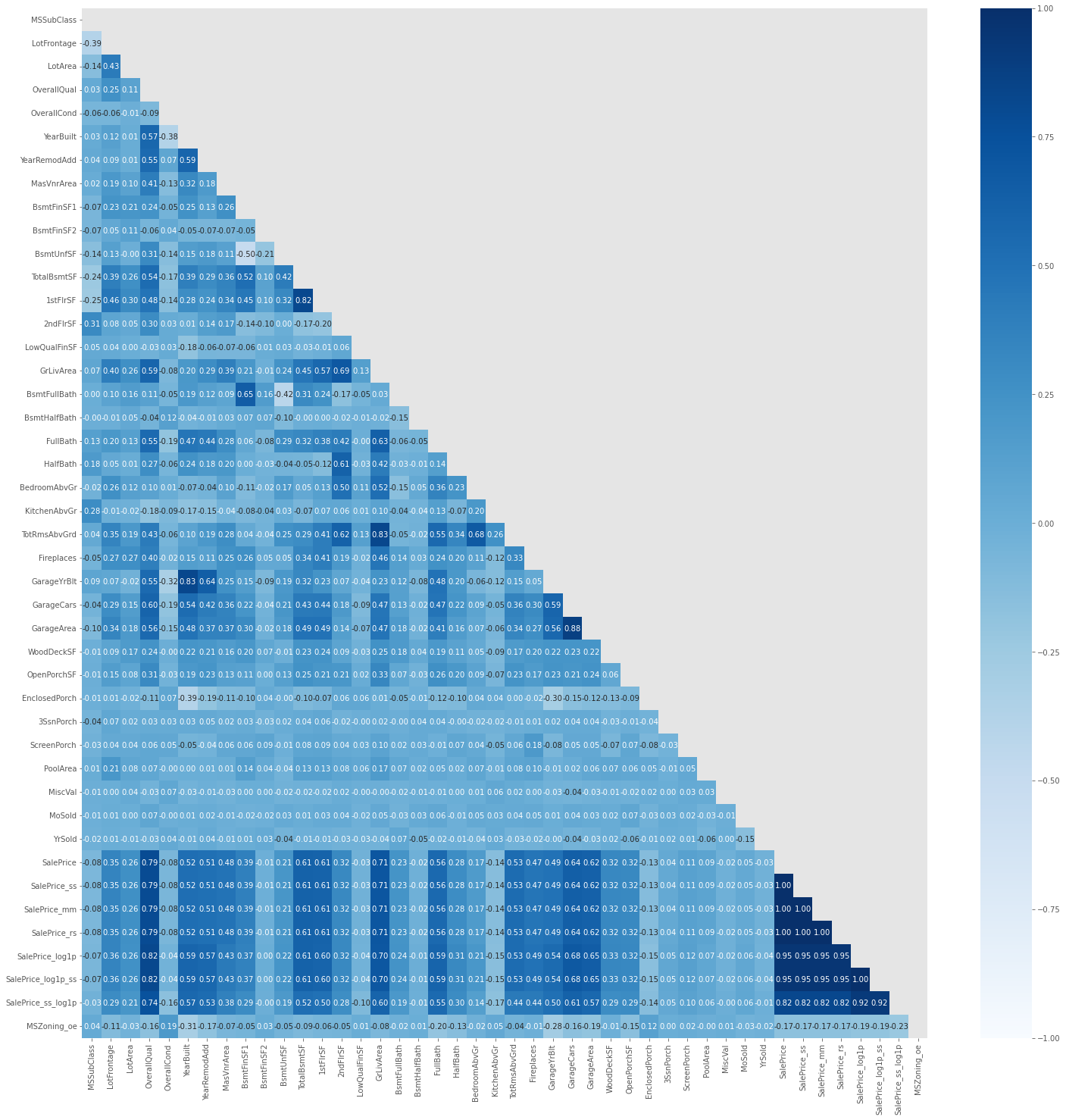
“YearBuilt”와 “GarageYrBlt”의 상관계수가 높아보이는 것을 볼 수 있다. 조금 더 자세히 확인해보도록 아래와 같이 해보자.
# ["YearBuilt", "GarageYrBlt"]
# loc[행, 열]
corr.loc["YearBuilt", "GarageYrBlt"]
결과값 : 0.8256674841743408
train과 test 하나의 데이터로 합치기
train과 test를 합치는 이유에는 장단점이 존재한다. 장점으로는 전처리 과정을 한번만 해도 되는 것이지만, 단점으로는 test에만 있는 피처에 사용하면 안되는 정책이 있을 때는 정책위반의 가능성이 있다.
df = pd.concat([train, test])
df.shape
결과값 : (2919, 80)
EDA
정답값 label 따로보기
# SalePrice 의 displot
# aspect = plotly의 width와 같은 의미로, 그래프의 너비(가로길이)를 의미한다.
sns.displot(data = df, x = "SalePrice", aspect = 5)
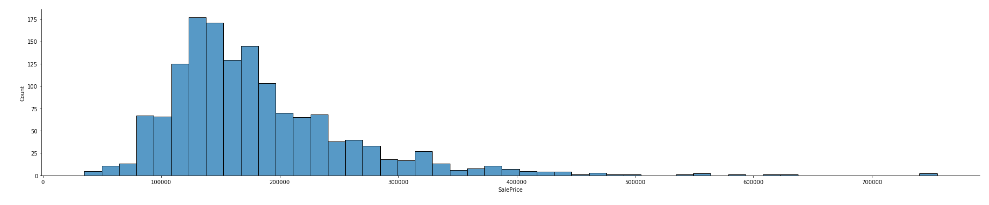
sns.displot(data = df, x = "SalePrice", aspect = 5, rug = True, kind = "kde")

왜도와 첨도
- 비대칭도(非對稱度, skewness) 또는 왜도(歪度)는 실수 값 확률 변수의 확률 분포 비대칭성을 나타내는 지표이다. 왜도의 값은 양수나 음수가 될 수 있으며 정의되지 않을 수도 있다.
- 왜도가 음수일 경우에는 확률밀도함수의 왼쪽 부분에 긴 꼬리를 가지며 중앙값을 포함한 자료가 오른쪽에 더 많이 분포해 있다.
- 왜도가 양수일 때는 확률밀도함수의 오른쪽 부분에 긴 꼬리를 가지며 자료가 왼쪽에 더 많이 분포해 있다는 것을 나타낸다.
- 평균과 중앙값이 같으면 왜도는 0이 된다.
- 첨도(尖度, 영어: kurtosis 커토시스)는 확률분포의 뾰족한 정도를 나타내는 척도이다. 관측치들이 어느 정도 집중적으로 중심에 몰려 있는가를 측정할 때 사용된다.
- 첨도값(K)이 3에 가까우면 산포도가 정규분포에 가깝다.
- 3보다 작을 경우에는(K<3) 정규분포보다 더 완만하게 납작한 분포로 판단할 수 있으며,
- 첨도값이 3보다 큰 양수이면(K>3) 산포는 정규분포보다 더 뾰족한 분포로 생각할 수 있다.
SalePrice의 왜도와 첨도를 구해본다.
# SalePrice 의 왜도와 첨도를 구합니다.
print("왜도(Skewness):", train["SalePrice"].skew())
print("첨도(Kurtosis):", train["SalePrice"].kurtosis())
결과값 :
왜도(Skewness): 1.8828757597682129
첨도(Kurtosis): 6.536281860064529
SalpPrice를 정규분포로 변환하고 왜도와 첨도를 다시 구해보도록 하자.
train["SalePrice_log"] = np.log1p(train["SalePrice"])
# histogram은 pandas기능을 이용하는 것을 추천.
train[['SalePrice_log', 'SalePrice']].hist(bins = 50, figsize = (10,5))
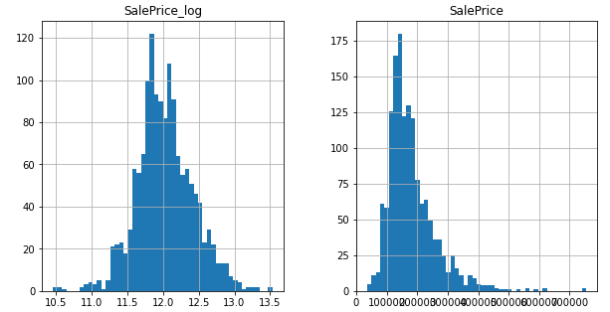
fig, ax = plt.subplots(ncols = 2, nrows = 1, figsize = (10,5))
sns.kdeplot(train['SalePrice_log'], fill = True, ax = ax[0])
sns.kdeplot(train['SalePrice'], fill = True, ax = ax[1])
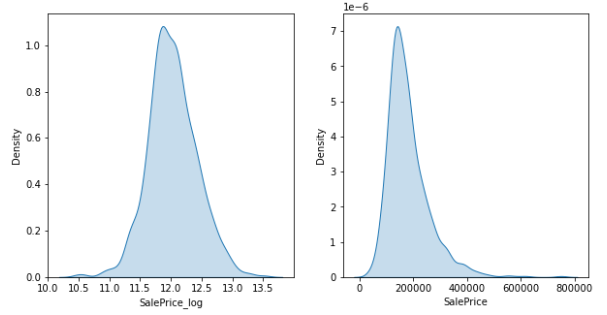
np.log1p변환을 통해서 SalePrice를 정규분포로 만들어주었다.
결측치 보기
결측치 수와 비율을 함께 보고 싶다면 합계와 비율을 구해서 concat으로 합쳐주면 보기 좋게 출력을 해 줄 수있다.
isna_sum = df.isnull().sum()
isna_mean = df.isnull().mean()
pd.concat([isna_sum, isna_mean], axis = 1).nlargest(10, 1)
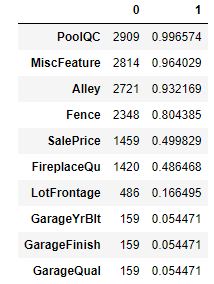
결측치의 비율이 80%가 넘어가는 feature들은 제외를 해주도록 하자.
null_feature = isna_mean[isna_mean > 0.8].index
null_feature
결과값 : Index(['Alley', 'PoolQC', 'Fence', 'MiscFeature'], dtype='object')
제거가 잘 되었는지 확인을 해보도록 한다.
df = df.drop(columns = null_feature)
print(df.shape)
# 어떤 피처가 삭제되었는지 확인
set(test.columns) - set(df.columns)
결과값 :
(2919, 76)
{'Alley', 'Fence', 'MiscFeature', 'PoolQC'}
수치형 변수
집값과 상관계수가 높은 데이터 보기
# 위에서 df가 변경되었기 때문에 상관계수 변수를 다시 설정해준다.
corr = df.corr()
corr.loc[(abs(corr["SalePrice"]) > 0.6), "SalePrice"]
결과값 :
OverallQual 0.790982
TotalBsmtSF 0.613581
1stFlrSF 0.605852
GrLivArea 0.708624
GarageCars 0.640409
GarageArea 0.623431
SalePrice 1.000000
Name: SalePrice, dtype: float64
# SalePrice와 상관계수가 특정 수치 이상인 변수의 인덱스를 확인한다.
high_corr_col = corr.loc[(abs(corr["SalePrice"]) > 0.5), "SalePrice"].index
high_corr_col
결과값 :
Index(['OverallQual', 'YearBuilt', 'YearRemodAdd', 'TotalBsmtSF', '1stFlrSF',
'GrLivArea', 'FullBath', 'TotRmsAbvGrd', 'GarageCars', 'GarageArea',
'SalePrice'],
dtype='object')
pairplot을 통해서 모든 변수들에 대한 이상치, 상관계수, 왜도, 첨도 등을 한눈에 볼 수 있다.
# 위에서 그렸던 상관계수가 높은 변수만 그려본다.
sns.pairplot(train[high_corr_col], corner = True)
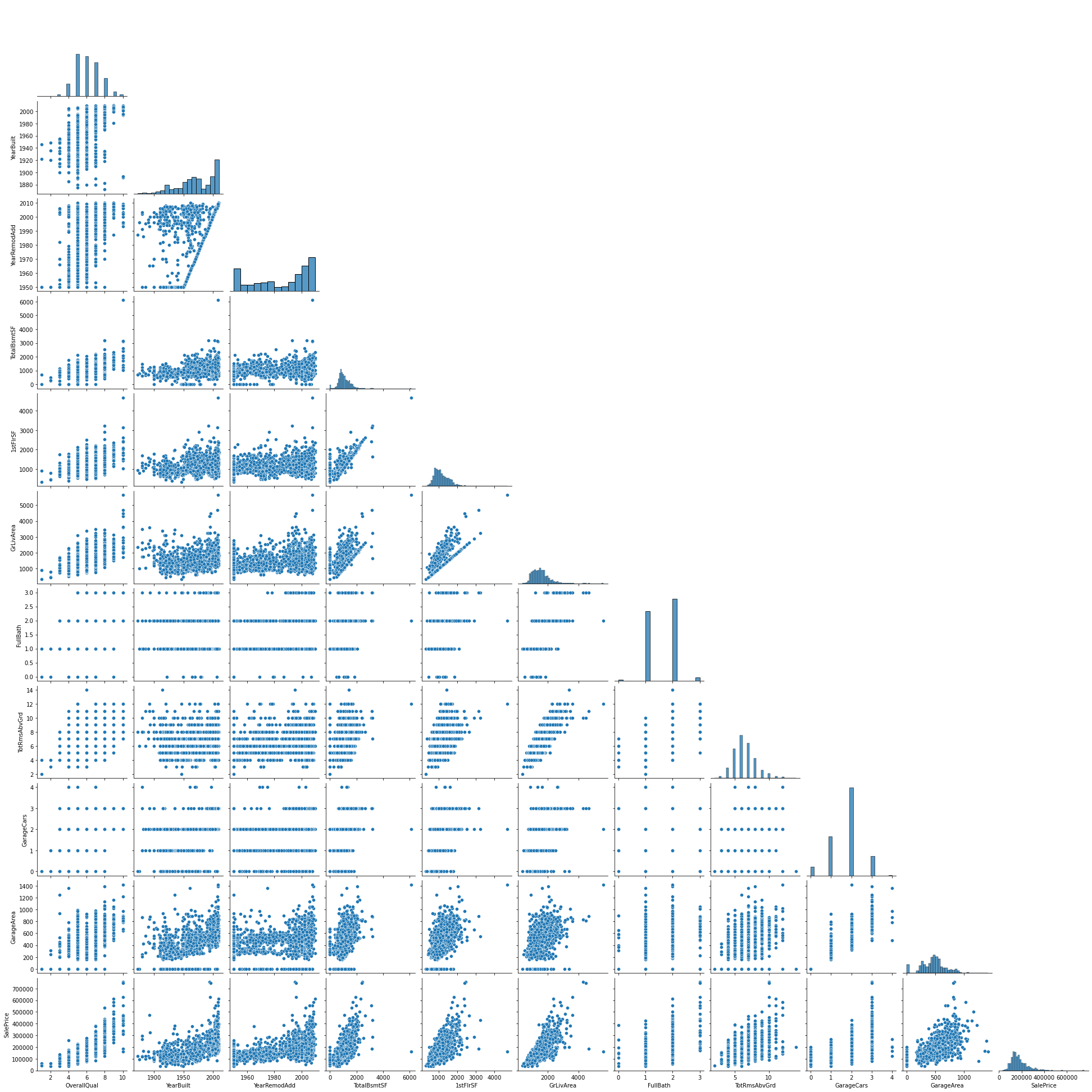
파생변수 만들기
SF항목을 가진 Feature들이 존재한다. 이들을 하나의 Feature로 합쳐주도록 하자.
# TotalSF = TotalBsmtSF + 1stFlrSF + 2ndFlrSF
df["TotalSF"] = df["TotalBsmtSF"] + df["1stFlrSF"] + df["2ndFlrSF"]
결측치 채우기
0이나 None으로 채우기
# Garage 관련 범주형 변수 'None' 으로 결측치 대체
Garage_None = ['GarageType', 'GarageFinish', 'GarageQual', 'GarageCond']
df[Garage_None] = df[Garage_None].fillna('None')
# Garage 관련 수치형 변수 0 으로 결측치 대체
Garage_0 = ['GarageYrBlt', 'GarageArea', 'GarageCars']
df[Garage_0] = df[Garage_0].fillna(0)
# Basement 관련 수치형 변수 0 으로 결측치 대체
Basement_0 = ['BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath']
df[Basement_0] = df[Basement_0].fillna(0)
# Basement 관련 범주형 변수 'None' 으로 결측치 대체
Basement_None = ['BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2']
df[Basement_None] = df[Basement_None].fillna('None')
최빈값으로 채우기
fill_mode = ['MSZoning', 'KitchenQual', 'Exterior1st', 'Exterior2nd', 'SaleType', 'Functional']
# df[fill_mode].describe().loc[0]과 같은 결과를 보여준다.
df[fill_mode].mode().loc[0]
결과값:
MSZoning RL
KitchenQual TA
Exterior1st VinylSd
Exterior2nd VinylSd
SaleType WD
Functional Typ
Name: 0, dtype: object
# 결칙치를 최빈값으로 채운다.
df[fill_mode] = df[fill_mode].fillna(df[fill_mode].mode().loc[0])
없었던 값으로 채웠는지 확인하기 위해서 아래와 같이 실행하도록 한다.
df[fill_mode[0]].value_counts()
결과값:
RL 2269
RM 460
FV 139
RH 26
C (all) 25
Name: MSZoning, dtype: int64
데이터 타입 바꾸기
우리가 사용할 feature들이 수치형인지, 변수형인지를 파악하기 위해서 수치형 변수들을 파악하기로 한다.
수치 데이터의 nunique 구해서 어떤 값을 one-hot-encoding하면 좋을지 찾아보도록 한다. 수치 데이터를 그대로 ordinal encoding 된 값을 그대로 사용해도 되지만 범주값으로 구분하고자 category나 object 타입으로 변환하면 one-hot-encoding 할 수 있다. ordinal encoding -> one-hot-encoding 으로 변환하는 것이 실습 목적이다.
# select_dtypes : 머신러닝에서 많이 사용하는 기능
num_nunique = df.select_dtypes(include = "number").nunique().sort_values()
num_nunique[num_nunique < 10]
# MSSubClass=The building class
# Changing OverallCond into a categorical variable
# Year and month sold are transformed into categorical features.
num_to_str_col = ["MSSubClass", "OverallCond", "YrSold", "MoSold"]
df[num_to_str_col].nunique()
결과값 :
MSSubClass 16
OverallCond 9
YrSold 5
MoSold 12
dtype: int64
# num_to_str_col의 타입을 string으로 바꿔주자.
# 문자 형태로 변경하게 되면 나중에 pd.get_dummies 로 인코딩 했을 때 원핫인코딩을 한다.
df[num_to_str_col] = df[num_to_str_col].astype(str)
df[num_to_str_col].dtypes
결과값:
MSSubClass object
OverallCond object
YrSold object
MoSold object
dtype: object
나머지 수치 변수 중앙값으로 결측치 대체
# 수치형 변수 찾기
feature_num = df.select_dtypes(include="number").columns.tolist()
feature_num.remove("SalePrice")
feature_num
# 수치형 변수 모두 중앙값으로 대체
df[feature_num] = df[feature_num].fillna(df[feature_num].median())
