House Price 경진대회의 데이터 전처리, 모델링 및 학습과 Benz Grenner Manufacturing 데이터 전처리
⚠️ 해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료를 토대로 정리한 내용입니다.
지난 포스트에서 이어짐
⚠️ 결측치/이상치 제거시 주의사항
결측치가 많다고 삭제하는게 무조건 나은 방법이 아닐 수도 있다. 이상치, 특잇값을 찾는다면 오히려 특정 값이 신호가 될 수도 있다. 범주형 값이라면 결측치가 많더라도 채우지 않고 인코딩해주면 나머지 없는 값은 0으로 채워지게 되는 대신 희소한 행렬이 생성된다. 그리고, 수치데이터인데 결측치라면 잘못채웠을 때 문제가 많으니 주의가 필요하다. 언제 어떤 방법을 사용해야할지 모르겠다면 노트북 필사를 여러 개 해보고 다양한 데이터셋을 다뤄보는것을 추천한다. 지금까지 다뤄본 데이터셋이 많지 않기 때문에 좀 더 수련이 필요하고, 경험치를 많이 쌓는게 중요하다.
🤔 왜도와 첨도의 정확한 수치까지 알아야할 필요가 있나요?
정확한 수치까지 모르더라도 시각화를 해보면 알 수 있으나, 변수가 100개 그 이상이라면? 하나씩 다 비교해 볼 수 있지만 많은 시간이 소요된다. Anscombe’s Quartet 데이터를 생각해 보면 요약된 기술 통계는 데이터를 자세히 설명하지 못하는 부분도 있을 수 있다. 그래서 왜도와 첨도는 변수가 수백개 될 때 전체적으로 왜도와 첨도가 높은 값을 추출해서 전처리를 해 줄 수 있다. 지난 번 실습했던 예를 보면 왜도나 첨도가 높은 값을 추출해서 변환하는 전처리를 진행할 수도 있다. pandas, numpy 등으로 기술통계를 구해보면 왜도, 첨도(기본 값 피셔의 정의 일 때) 0에 가까울 때 정규분포에 가까운 모습을 보인다.
log 변환
log_features = ['LotFrontage','LotArea','MasVnrArea','BsmtFinSF1','BsmtFinSF2','BsmtUnfSF',
'TotalBsmtSF','1stFlrSF','2ndFlrSF','LowQualFinSF','GrLivArea',
'BsmtFullBath','BsmtHalfBath','FullBath','HalfBath','BedroomAbvGr','KitchenAbvGr',
'TotRmsAbvGrd','Fireplaces','GarageCars','GarageArea','WoodDeckSF','OpenPorchSF',
'EnclosedPorch','3SsnPorch','ScreenPorch','PoolArea','MiscVal','YearRemodAdd']
위 log_features 중에서 수치형 변수만 log로 변환해주도록 하자.
num_cat_feature = df[log_features].nunique()
# nunique의 값이 20개 이하인 feature를 탐색한다. 값이 적다는 것은 분류형일 가능성이 높다.
num_cat_feature = num_cat_feature[num_cat_feature < 20].index
# log_features에서 분류형 feature인 num_cat_feature를 제외한다.
num_cat_feature = list(set(log_features) - set(num_cat_feature))
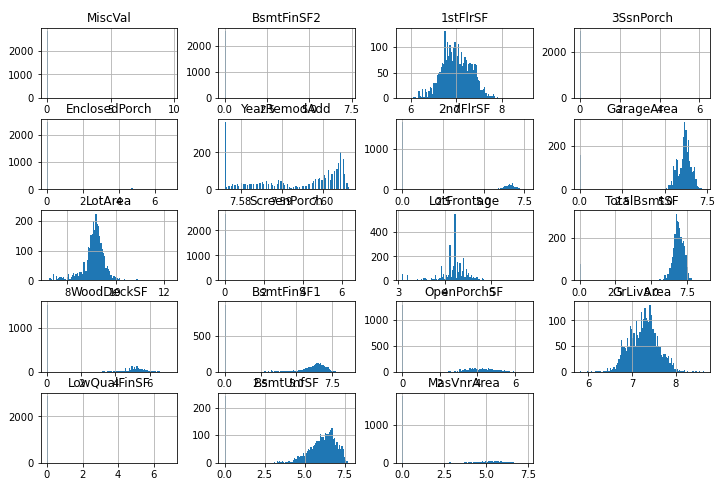
df[num_cat_feature] = np.log1p(df[num_cat_feature])
df[num_cat_feature].hist(bins = 100, figsize = (12,8));
squared features (Polynomials)
squared features를 해줄 feature를 선정해준다.
squared_features = ['YearRemodAdd', 'LotFrontage',
'TotalBsmtSF', '1stFlrSF', '2ndFlrSF', 'GrLivArea',
'GarageCars', 'GarageArea']
df[squared_features].hist(figsize=(12, 8), bins=50)
plt.show()
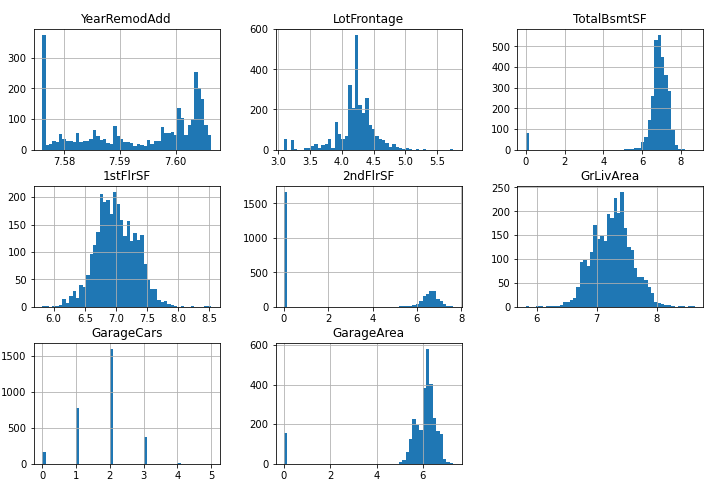
사이킷 런에서 Polynomials로 변수를 만드는 기능을 제공하고 있지만, 직접 제곱을 해줘도 된다. 유니폼한 분포에 사용한다. 여기에서는 사용할만한 변수가 보이지 않지만, Polynomials를 사용해 볼 수 있다는 점을 고려하자.
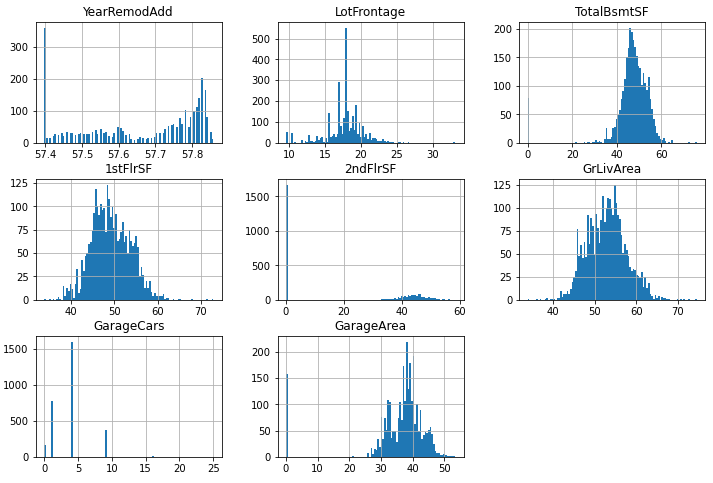
# squared_features
df_square = df[squared_features] ** 2
histplot을 이용해서 시각화를 하여 차이를 확인해본다. uniform한 분포가 아니기 때문에 여기에서는 사용하지 않아도 괜찮아 보인다. 값을 강조해서 구분하고자 할 때 주로 사용한다.
df_square.hist(figsize=(12, 8), bins = 100);
범주형 변수 보기
범주형 변수에서 결측치가 없는 변수 찾아낸다. 범주형 변수 중 결측치가 있는지 확인해보고 어떤 범주형 변수를 선택해서 모델에 사용할지 의사결정을 하게 된다. 위에서 이미 결측치를 대부분 채워줬기 때문에 대부분의 결측치가 처리되었고, 일부만 남아있다. 정렬을 하고 결측치가 있는 데이터를 제거하기 위해 슬라이싱을 사용하도록 한다. 범주형 데이터는 원핫인코딩을 작업하지 않기 때문에 결측치를 남겨도 상관없다(없는 값은 변수로 생성하지 않는다).
df_cate = df.select_dtypes(include="object")
df_cate.isnull().mean().sort_values()
-
결과값
MSSubClass 0.000000 BsmtQual 0.000000 BsmtCond 0.000000 BsmtExposure 0.000000 BsmtFinType1 0.000000 BsmtFinType2 0.000000 Heating 0.000000 HeatingQC 0.000000 CentralAir 0.000000 KitchenQual 0.000000 Functional 0.000000 GarageType 0.000000 GarageFinish 0.000000 GarageQual 0.000000 GarageCond 0.000000 PavedDrive 0.000000 MoSold 0.000000 YrSold 0.000000 SaleType 0.000000 ExterCond 0.000000 Foundation 0.000000 Condition1 0.000000 MSZoning 0.000000 Street 0.000000 LotShape 0.000000 LandContour 0.000000 LotConfig 0.000000 LandSlope 0.000000 Neighborhood 0.000000 ExterQual 0.000000 SaleCondition 0.000000 Condition2 0.000000 BldgType 0.000000 HouseStyle 0.000000 OverallCond 0.000000 RoofStyle 0.000000 RoofMatl 0.000000 Exterior1st 0.000000 Exterior2nd 0.000000 Electrical 0.000343 Utilities 0.000685 MasVnrType 0.008222 FireplaceQu 0.486468 dtype: float64
마지막 두개의 변수들을 제거한 새로운 feature의 묶음을 만들도록 한다.
feature_cate = df_cate.isnull().mean().sort_values()[:-2].index
Make feature
label name
label_name변수에 예측에 사용할 정답값을 지정한다.
label_name = "SalePrice_log1p"
🤔 정답값이 왜 log1p인가?
경진대회의 submition을 확인해보자. Submissions are evaluated on Root-Mean-Squared-Error (RMSE) between the logarithm of the predicted value and the logarithm of the observed sales price. (Taking logs means that errors in predicting expensive houses and cheap houses will affect the result equally.) 집값을 2억=>4억으로 예측하는 모델로 100억=>110억으로 예측했을 때 어디에 더 패널티를 줄 것인지를 생각해보면 MAE(오차의 절대값)는 첫번째는 2억차이, 두번째는 10억으로 판단한다. 반면, MSE는 첫번째는 4억차이, 두번째는 100억차이로 책정하며 오차가 크면 클수록 값은 더 벌어진다. RMSLE의 경우, 첫번째는 np.log(2) => 0.69, 두번째는 np.log(10) => 2.30으로 평가한다. 즉, 로그값은 작은 값에서 더 패널티를 주고 값이 커짐에 따라 완만하게 증가하게 된다. 로그값이 작은 값에서 더 패널티를 주는 것은 로그 그래프를 떠올려 보는 것이 도움이 될 것이다.
Feature names
feature_names = []
feature_names.extend(num_log_feature)
feature_names.append("TotalSF")
feature_names.extend(feature_cate)
feature_names.remove("1stFlrSF")
feature_names.remove("2ndFlrSF")
feature_names.remove("BsmtFinSF1")
feature_names.remove("BsmtFinSF2")
feature_names
-
결과값
['MiscVal', '3SsnPorch', 'EnclosedPorch', 'YearRemodAdd', 'GarageArea', 'LotArea', 'ScreenPorch', 'LotFrontage', 'TotalBsmtSF', 'WoodDeckSF', 'OpenPorchSF', 'GrLivArea', 'LowQualFinSF', 'BsmtUnfSF', 'MasVnrArea', 'TotalSF', 'MSSubClass', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'Heating', 'HeatingQC', 'CentralAir', 'KitchenQual', 'Functional', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond', 'PavedDrive', 'MoSold', 'YrSold', 'SaleType', 'ExterCond', 'Foundation', 'Condition1', 'MSZoning', 'Street', 'LotShape', 'LandContour', 'LotConfig', 'LandSlope', 'Neighborhood', 'ExterQual', 'SaleCondition', 'Condition2', 'BldgType', 'HouseStyle', 'OverallCond', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'Electrical', 'Utilities']
One-Hot-Encoding
df_ohe = pd.get_dummies(data = df[feature_names])
# 원핫인코딩 후 기존 데이터와 개수를 비교
df.shape, df_ohe.shape
결과값 :
((2919, 77), (2919, 297))
데이터셋 만들기
# train, test 데이터셋 나누기
train.index, test.index
# X, y로 학습과 예측 데이터 만들어주기
X_train = df_ohe.loc[train.index]
X_test = df_ohe.loc[test.index]
y_train = train[label_name]
러닝머신 모델
회귀 예측이기 때문에 RandomForestRegressor를 사용하도로고 한다.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(random_state= 42)
KFold 로 Cross Validation 하기
# KFold 를 사용해서 분할을 나눕니다.
# 분할에 random_state를 사용할 수 있다.
# 분할 때문에 값이 변경된건지 실험을 좀 더 고정할 수 있다.
from sklearn.model_selection import KFold
# KFold : 먼저 K개의 데이터 폴드 세트를 만들어서 K번만큼 각 폴드 세트에 학습고 검증 평가를 1반복적으로 수행하는 방법
kf = KFold(random_state=42, n_splits = 5, shuffle=True)
cross_val_score 와 cross_val_predict 로 점수 구하기
from sklearn.model_selection import cross_val_predict
y_val_pred = cross_val_predict(model, X_train, y_train, cv = kf, n_jobs = -1)
Metric
RMSE로 오차 측정을 계산해준다.
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_train, y_val_pred)
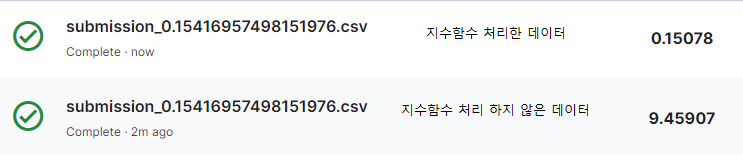
결과값 : 0.02376825784998244
rmse = np.sqrt(mse)
결과값 : 0.15416957498151976
실제값과 예측값 비교하기
# regplot 으로 예측값에 대한 회귀선 그리기
sns.regplot(x=y_train, y = y_val_pred)
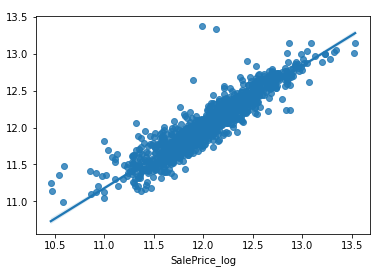
R2 Score로 오차 측정
R2 Score는 1에 가까운 큰 값일 수록 잘 예측한 값이다.
from sklearn.metrics import r2_score
r2_score(y_train, y_val_pred)
결과값 : 0.8509363870476118
KDE Plot
sns.kdeplot(y_train)
sns.kdeplot(y_val_pred)
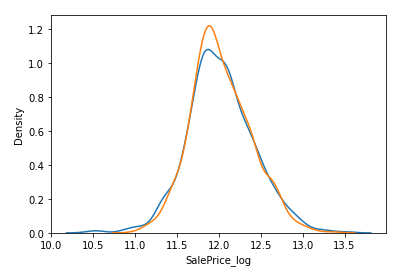
학습(훈련) 및 예측
# 학습 과 예측을 한번에 진행해준다.
y_pred = model.fit(X_train, y_train).predict(X_test)
feature 중요도 보기
전과 다르게 이번 데이터에는 feature가 굉장히 많기 때문에 전과 동일하게 진행하면 피처 중요도의 시각화가 제대로 이루어지지 않는다. 따라서, 상위 20개의 중요 데이터만 따로 시각화를 진행하도록 한다.
# 중요도 상위 피처만 가져오기
fi = pd.Series(model.feature_importances_)
fi.index = model.feature_names_in_
fi.nlargest(20)
# 피처 중요도 시각화 하기
fi.nlargest(20).plot.barh()
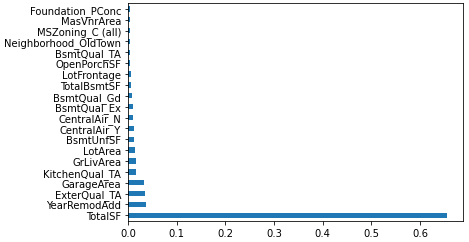
Submit
⚠️ 정답값을 입력하기 전에 지수함수 처리(np.expm1)를 해서 원래 스케일로 복원해줘야 한다!
리더보드에 있는 점수와 동일한 스케일 점수를 미리 계산해보기 위해서는 로그 적용 값으로 계산해주지만, 제출할 떄는 지수함수를 적용해서 원래 스케일로 복원하여 제출해야 제대로 된 점수를 평가받을 수 있다.
💡 전처리 방법 요약
수치형
- 결측치 대체(Imputation)
- 수치형 변수를 대체할 때는 원래의 값이 너무 왜곡되지 않는지도 주의가 필요.
- 중앙값(중간값), 평균값 등의 대표값으로 대체할 수도 있지만, 당뇨병 실습에서 했던 회귀로 예측해서 채우는 방법도 있다.
- 당뇨병 실습에서 했던 인슐린을 채울 때 당뇨병 여부에 따라 대표값을 구한 것 처럼 여기에서도 다른 변수를 참고해서 채워볼 수도 있다.
- 스케일링 - Standard, Min-Max, Robust
- 변환 - log
- 이상치(너무 크거나 작은 범위를 벗어나는 값) 제거 혹은 대체
- 오류값(잘못된 값) 제거 혹은 대체
- 이산화 - cut, qcut
범주형
- 결측치 대체(Imputation)
- 인코딩 - label, ordinal, one-hot-encoding
- 범주 중에 빈도가 적은 값은 대체하기
Mercedes-Benz Greener Manufacturing
머신러닝의 필요성
제조업에서 데이터 과학과 머신러닝의 이점?
- 품질관리
- 예방 정비
- 수요예측
- 프로세싱 조건(생산 과정에서 여러 변수들의 역학관계 파악을 자동화하여 공정을 최적화)
- 연구개발(생산 과정에서 얻어낸 빅데이터와 이를 기반으로 한 머신러닝은 새로운 제품을 개발하거나 다른 기업과 협업)
- 스마트 제품
- 산업 프로세스를 혁신하는 머신러닝 기술 활용 사례
선형 회귀(Linear Regression)
- 선형 회귀(linear regression)는 종속 변수 y와 한 개 이상의 독립 변수 (또는 설명 변수) X와의 선형 상관 관계를 모델링하는 회귀분석 기법.
- 선형 회귀는 선형 예측 함수를 사용해 회귀식을 모델링하며, 알려지지 않은 파라미터는 데이터로부터 추정한다.
데이터 로드
# train, test, submisson 데이터 셋을 호출한다.
# data를 받을 때 .csv.zip으로 확장자가 기존과 다른데 바꿔줄 필요는 없다.
train = pd.read_csv(f'{base_path}/train.csv.zip', index_col="ID")
test = pd.read_csv(f'{base_path}/test.csv.zip', index_col="ID")
submission = pd.read_csv(f'{base_path}/sample_submission.csv.zip', index_col="ID")
# train의 데이터셋을 간단히 살펴본다
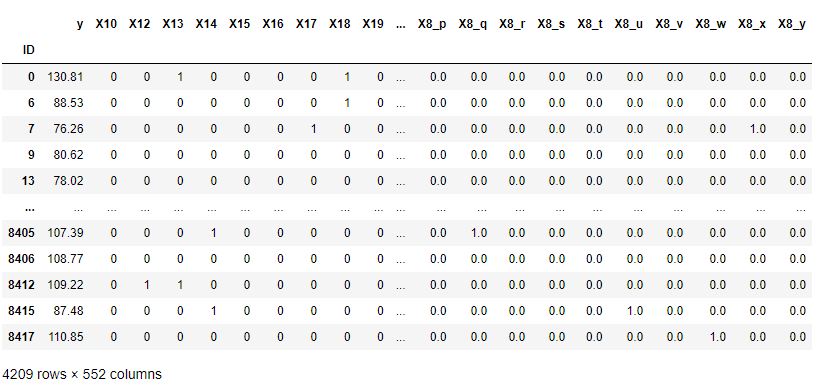
train.head(2)

데이터를 살펴보면 어떤 지표들인지 인지하기가 어렵다. 이는 벤츠에서 경진대회를 개최했을 때 사내 보안상의 이유로 인해 데이터들을 일종의 암호화로 처리해서 공개한 것이다.
X는 feature, 독립변수, 2차원 array 형태, 학습할 피처, 예) 시험의 문제
y는 label, 종속변수, target, 정답, 1차원 벡터, 예) 시험의 정답
여기서 ‘y’는 제조 과정에서 테스트 단계에 드는 시간을 예측을 의미한다.
# test를 확인합니다.
test.head(2)
# sub를 확인합니다.
submission.head(2)

EDA
# info
train.info()
결과값:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 4209 entries, 0 to 8417
Columns: 377 entries, y to X385
dtypes: float64(1), int64(368), object(8)
memory usage: 12.1+ MB
# describe
train.describe()
기술통계값(describe)를 구해보니 너무 많은 feature들이 존재한다. 이 중에서 필요 없는 값이 있는지를 확인해보자.
# nunique
train_nunique = train.nunique().sort_values()
train_nunique
결과값:
X290 1
X235 1
X11 1
X297 1
X347 1
...
X1 27
X5 29
X2 44
X0 47
y 2545
Length: 377, dtype: int64
1인 feature들이 다수 있는 것으로 보인다. 해당 feature들을 제거하고 진행해보도록 한다.
# 값이 1인 데이터 찾기
train_one_idx = train_nunique[train_nunique == 1].index
train_one_idx
결과값:
Index(['X290', 'X235', 'X11', 'X297', 'X347', 'X268', 'X107', 'X293', 'X330',
'X289', 'X93', 'X233'],
dtype='object')
해당 값들의 describe()를 확인해보자.
train[train_one_idx].describe()
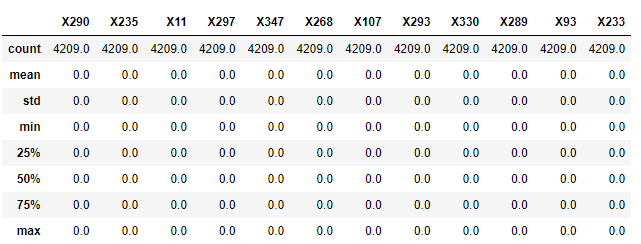
기술통계값을 보면 모두 같은 값이 있고 결측치가 없다. 또한, 0으로만 되어 있기 때문에 모두 삭제해도 문제가 없어보인다.
# 필요없는 데이터 제거
# 위 코드는 한번만 실행하는 것을 추천한다.
# 2번 이상 하면 에러를 유발할 수 있다.
train = train.drop(columns=train_one_idx)
test = test.drop(columns=train_one_idx)
이제 heatmap을 통해서 기술통계값을 구하도록 한다. 기존의 기술통계를 구했을 때 수치데이터가 너무 많기 때문에 일단 시각화 하여 표현해본다. 정답인 y를 제외하고 어떤 값이 크고 작은지 확인하도록 한다.
plt.figure(figsize = (15,15))
sns.heatmap(train.select_dtypes(include="number").drop(columns = "y"), cmap = "Greys")

모든 수치데이터가 0~1 사이의 값이다. 이는 Min-Max 범위조정이 되어 있어 스케일링 할 필요가 없어 보인다. 즉 , 이 데이터는 정규화되어 제공되고 있는 데이터라는 것을 확인할 수 있다.
One-Hot-Encoding
OneHotEncoder는 전체 데이터를 변환하기 때문에 범주형 뿐만 아니라 수치 데이터 모두 인코딩한다.
그래서 범주값 데이터만 따로 넣어 인코딩해주어야 한다. pd.get_dummies()의 장점은 이런 전처리 없이 범주 데이터만 OneHotEncoding한다는 점이다. 그래서, 변수가 많을 때 OneHotEncoder나 pd.get_dummise()를 사용하는 것이 좋다.
from sklearn.preprocessing import OneHotEncoder
# handle_unknown : train에는 등장하지만, test에는 없다면 무시한다.
# drop : OHE를 할 때 어떤 컬럼을 생성하지 않는지에 대한 옵션이다.
# if_binary : binary 같은 경우만 한개를 버리게 한다.
ohe = OneHotEncoder(drop="if_binary", handle_unknown="ignore")
# train을 기준으로 feature를 만드는데, test에는 train에 없는 값이 있다면 그 값은 feature로 만들지 않는다.
# fit은 train을 기준으로 삼기 때문에 train만 진행한다.
# transform은 train, test 둘다 진행한다.
train_ohe = ohe.fit_transform(train.select_dtypes(exclude="number"))
test_ohe = ohe.transform(test.select_dtypes(exclude="number"))
print(train_ohe.shape, test_ohe.shape)
결과값 : (4209, 195) (4209, 195)
# 반환값이 np.array 형태이기 때문에 데이터프레임으로 별도의 변환이 필요하다.
df_train_ohe = pd.DataFrame(train_ohe.toarray(), columns = ohe.get_feature_names_out())
df_test_ohe = pd.DataFrame(test_ohe.toarray(), columns = ohe.get_feature_names_out())
인코딩한 분류형 변수들을 원래 df와 결합을 진행한다.
# 수치형 변수들만 따로 뽑아낸다.
train_num = train.select_dtypes(include="number")
# 수치형 변수와 전처리된 분류형 변수를 합친다.
pd.concat([train_num, df_train_ohe], axis = 1)